

In April, Jon Seager of Canonical laid out the company's plan for handling AI in Ubuntu. The framework split things into two groups, implicit AI that quietly improves what you already use and explicit AI that are features you'd actually summon on purpose.
Back then, Jon gave speech-to-text and text-to-speech as one of the examples of what an implicit feature could look like. Weeks later, one piece of that puzzle has materialized in the form of Myna.
While the tool is early in the development cycle, it is set to debut with Ubuntu 26.10, due out in October.
AI-powered accessibility begins
Jean-Baptiste Lallement, Canonical's Director of Engineering for Ubuntu Desktop, posted the announcement, saying that voice dictation has become a common feature across modern platforms.
For Ubuntu 26.10, the initial version of Myna is expected to be a desktop dictation tool built around GNOME on Wayland with a push-to-talk mechanism gatekeeping when your microphone accepts input.
Using it means holding a hotkey, speaking, and letting go. A small activity indicator shows while it is listening, and the transcribed text lands wherever the cursor was sitting when dictation started.
How will it work?
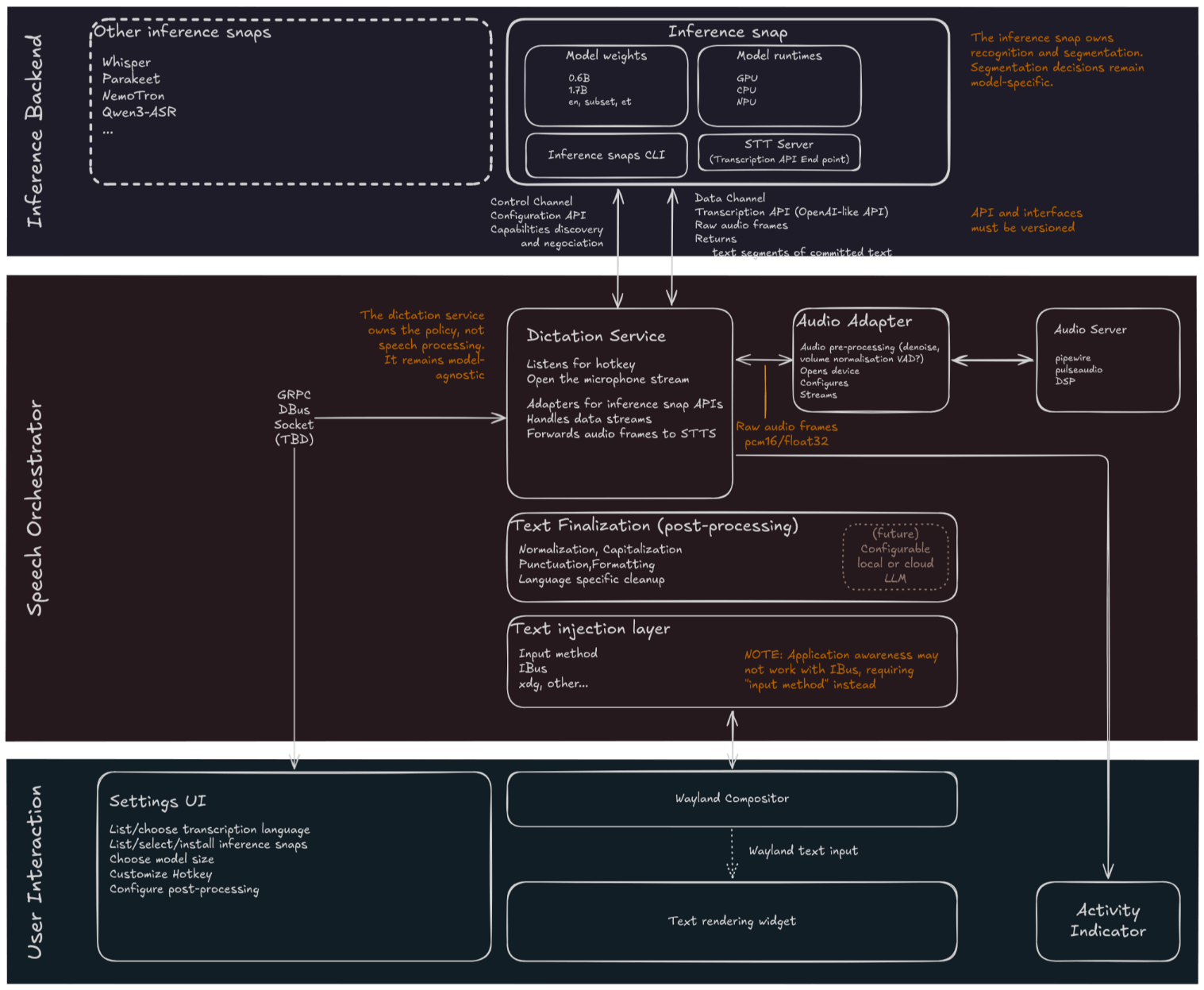
Recognition itself happens inside a sandboxed component called the Canonical Inference Snap, while a Speech Orchestrator manages the session and an Audio Adapter handles whatever the microphone picks up, denoising and chunking it before it ever reaches the model.
The snap is meant to carry speech models in three sizes, lightweight, default, and quality, along with a runtime to match whatever hardware is being used to run Myna. May it be an NVIDIA GPU, an Intel NPU, or just a CPU.
And before you yell, "my data would be sent to cloud servers!" know that speech recognition will happen locally, and an internet connection is not needed once the appropriate model is installed.
Moreover, text only appears once it is finalized, so you won't see half-formed words flicker the way some assistants show live captions. The audio data won't be sticking around either, being stored in a small in-memory buffer that gets discarded the moment the session ends.
Features like dictation into password fields, wake words, continuous listening, voice assistants, voice commands, translation, speaker identification, and automatic language detection are all off the table.
The fine print
None of this is locked in yet. The GitHub repository holds nothing more than a license, a README, and a folder for the documentation and architecture specs.
And, going by how past features have landed on interim Ubuntu releases, we could see Myna show up in the daily builds of Ubuntu 26.10 in the coming weeks.
You should also know that Canonical is looking for feedback before the specs for Myna are finalized, especially from people who already rely on dictation or assistive tools on Linux.
Enjoyed this update? Support independent Linux news coverage
It's FOSS has been helping people use Linux for the past 14 years. Help us stay independent from big tech. Become a Plus member, enjoy ad-free reading and get 5 eBooks.

