
In this AI based Science article, we explore How Netflix adopted an Open Source Model to improve their Entertainment Recommender Systems.
First, let us discuss in brief, what Machine Learning basically means. In simple terms, Machine Learning is a technique by which a computer can “learn” from data, without using a complex set of different rules. This approach is mainly based on training a model from datasets. The better the quality of the datasets, the better the accuracy of the Machine Learning Model.
First, a quick look at Machine Learning and Deep Learning
There are mainly three forms of Machine Learning:
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
Supervised learning is based on training on labeled datasets.
Unsupervised learning uses unlabeled datasets.
Reinforcement learning is based on rewarding an algorithm based on its correct outcomes and punishing it if it fails in the attempt.
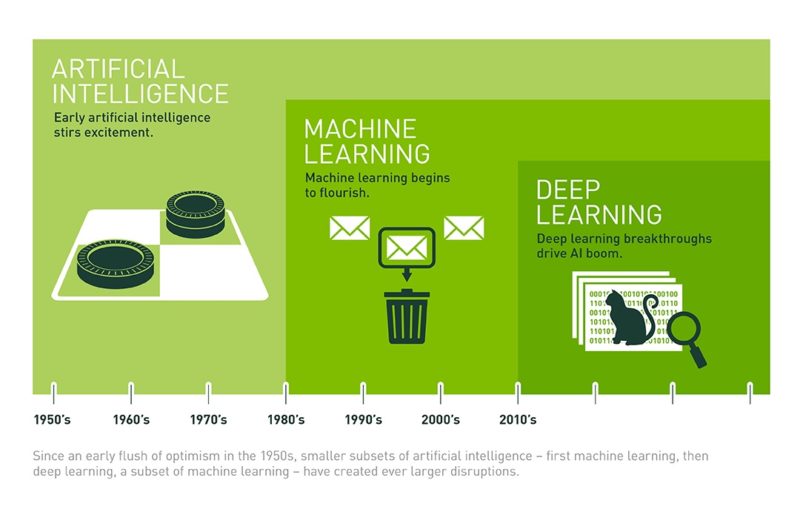

Relating to a subject widely known as Artificial Neural Networks, there is also “Deep Learning“, which is a technique to perform Machine Learning that is inspired by Our Brain’s Own Network of Neurons.
How Netflix uses AI for content recommendation
If you are or have been a Netflix subscriber, you most definitely know that Netflix does not use an advertisement-based model. Instead, they use a purely subscription-based model. This is why Netflix wants to make your experience as personified as possible for you.
In order to do that, Netflix started exploring a number of ways as to how they could come up with such a personally perceptive model. Even if you haven’t been a Netflix subscriber, you might have wondered about how Netflix makes those amazing recommendations on a user’s Netflix account and how people grew to love Netflix, which is so obvious in today’s time. You’d be surprised to know that some of these recommendations could have been based on the brain of a fruit fly!
In the beginning, their methodologies were very simple, based on Big Data and purely relying on a rating based system. Movie/TV Show recommendations were completely based on how good or bad a particular show or movie had been rated. These ratings were based on user feedback, number of views, whether videos were being watched in their entirety/parts and/or IMDB ratings.
Here’s a paper from Stanford University, dated March 12, 2008, that illustrates how Netflix’s recommendations were based on IMDB ratings.
Built upon a strong foundation of strategic decisions, Netflix has come a long way into building a great learning model to predict what their users’ next favourite unwatched movie could be, at a considerably high level of accuracy.
On September 21, 2009, a prize of $1M was awarded to team “BellKor’s Pragmatic Chaos” for improving Netflix’s recommendation model. Known as The Netflix Prize, this was an initiative by Netflix to enhance the user experience by 10% or more.
The prediction algorithm that was to be improvised and updated was based on collaborative filtering. Collaborative filtering is a recommendation technique that is completely based on collective user-derived feedback.
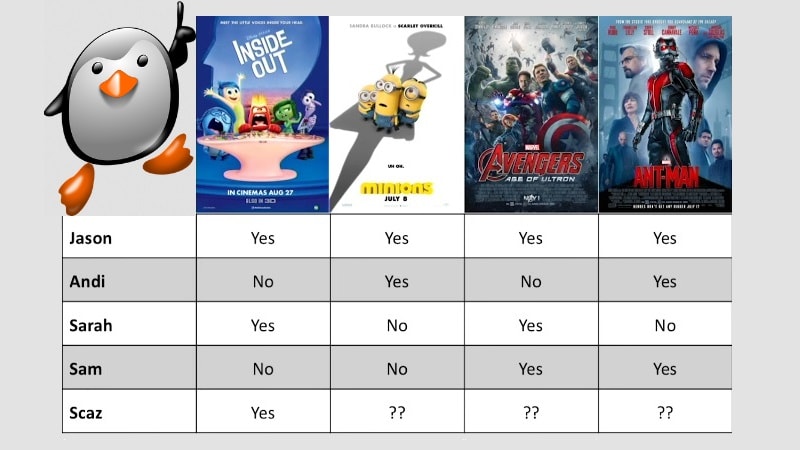
Say, a group of people has watched a movie which has a high possibility of you really liking it. But chances are you haven’t even heard of the movie before. By collecting and interpreting your past watching preferences with that of those who have completed watching it, a recommender system can suggest you that particular movie.
https://youtu.be/WQJXhCm5ffY
Content-based filtering, on the other hand, is not based on users’ preferences. Instead, comparisons are done among the videos themselves based on a type of classification, like a genre, for example. That could be a comedy, romance, horror, suspense and so on.
Further on, we also have a hybrid model that couples both of the above-described filtering techniques. If you want to learn about these in depth, please watch this clip:
Netflix even released a paper in the ACM journal titled “The Netflix Recommender System: Algorithms, Business Value, and Innovation”. The paper is available as open access. Some of the noticeable methodologies highlighted in the paper are as under:
Features & techniques Netflix use to deliver the best possible experience to their users:
- Personalized Video Ranker: PVR
- Top-N Video Ranker
- Trending Now
- Continue Watching
- Video-Video Similarity
- Page Generation: Row Selection and Ranking
- Evidence Selection
- Search Experience
- Statistical & Machine Learning Techniques for all of the above
To be able to relate to the above features, we went ahead and signed up for Netflix’s first-month free subscription and this is how the experience was:
After signing up, we had to choose 3 or more favorite movies or TV shows. So we chose Baahubali 2, Bright, Sherlock and Altered Carbon. There were many more choices to pick than shown below:
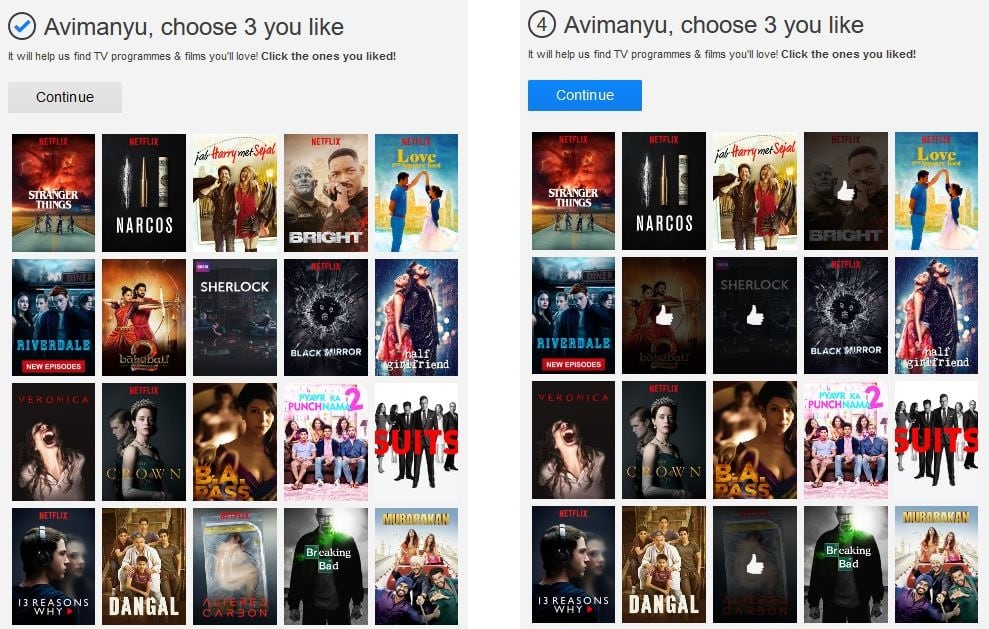
Following this, Netflix’s Artificial Brain sprung into action:
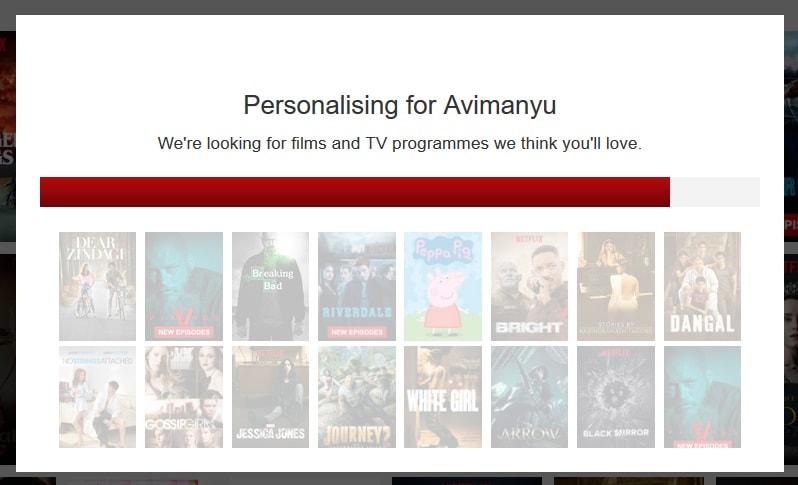
So, basically, the more the number of selection we would have made, the better the personalization would have been. Thereafter, we were greeted with the Netflix browsing page that looks like this:
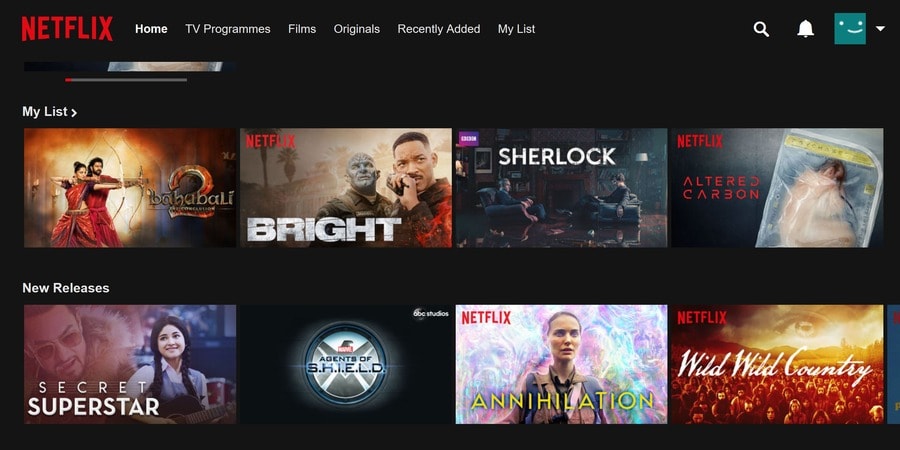
“My List” can be related to “Personalized Video Ranker: PVR”, corresponding to the first of the 9 techniques as listed above.
We had been wanting to watch “Altered Carbon” for quite some time. So we watched a few seconds of it in the beginning:
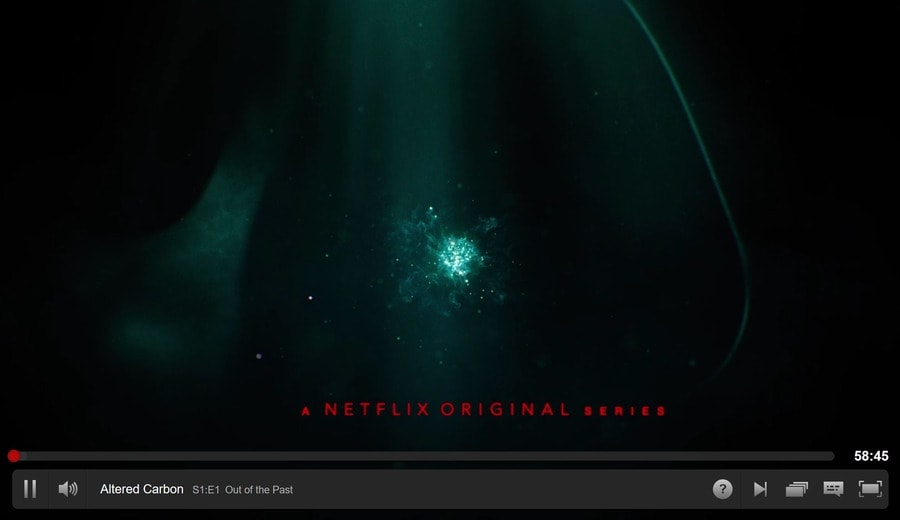
Coming back to the home page, we noticed a new recommendation:

This corresponds to “Video-Video Similarity” because we just watched a bit of “Altered Carbon”.
There was also another interesting recommendation row that showed us the top picks we could be interested in and we were surprised as we browsed through this list and found that there were none that we would not like to watch!
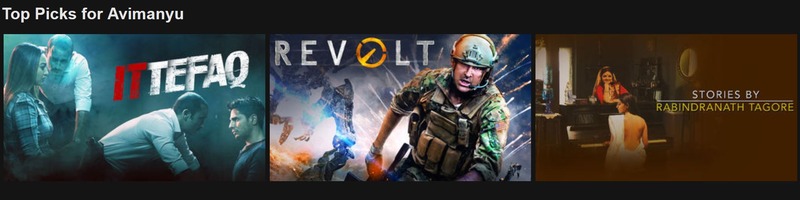
This would directly relate to “Top-N Video Ranker” from the list above. “Ittefaq” is a suspense thriller that belongs to a similar genre as that of “Sherlock” which we had chosen just after signing up. “Revolt” as the thumbnail suggests, must belong to an action genre, same as that of “Baahubali 2” or “Bright”. So this is derived from content-based filtering.
The recommendation, “Stories By Rabindranath Tagore”, surprised us even more. Netflix could have recommended this based on the location. They really have some incredibly mind-blowing algorithms out there!
So, that was a hands-on take on how Netflix practically works. All of these intelligent recommendations would not have been possible had Netflix not adopted an open source approach towards Artificial Intelligence and Machine Learning. Let us now look into the open source initiatives of Netflix.
Netflix Open Connect Initiative
Netflix’s very own content delivery network (CDN) is powered by open source. They initially outsourced their streaming services to Akamai, Level3 and Limelight. But eventually, they had a change in plans.
Netflix decided to build their own CDN because they wanted to:
- Grow Faster
- Reduce Costs
- Control the server side of HTTP connection
- Build a CDN specialized in Netflix Content Delivery
- Put the content closer to a client
Thus, Netflix Open Connect came into being. Namely, Netflix’s CDN foundation was built upon the NGINX web server and the FreeBSD operating system symbolizing two strong pillars. Netflix chose to use a BSD license instead of GPL while building their CDN. This was because ISPs were mainly involved as third parties. To compare both of these licenses in-depth, jump in here.
NGINX was chosen because it was known to be fast and stable, commercial support was available from Nginx, Inc. and it had a flexible framework for custom modules. FreeBSD was also known to be a fast and stable operating system and had a strong developer community. So, it became a suitable choice.
Both of the above being free and open source, Netflix used yet another open source project called the BIRD Internet Routing Daemon which, however, uses the GPL license. This tool was used to transfer network topology from ISPs to their own control system that would direct clients to their respective content.
All three served as great tools to handle:
- 400,000 stream files per appliance
- 5000-30,000 client streams per appliance
- 300-1000 clients per disk
The Open Connect Initiative as described above is discussed in detail in this comprehensive NGINX Conference recording:
Presentation slides here:
Netflix Open Source Software Initiative
Today, Netflix’s Open Source Software initiative speaks of their commitment towards open source. They have their very own Open Source Software Center! Netflix’s GitHub page clearly shows off their 139 repositories managed by 52 developers. All of the predictive results that we just saw hands-on, are powered by these unique open source projects listed on GitHub.
Netflix has their own deep learning library called Vectorflow, mentioned above. There is yet another predictive and analytical tool called Surus. It has a function known as ScorePMML that enables efficient scoring prediction of models in the cloud. Surus can also be used for outlier detection or pattern matching. Netflix has a blog post about them too.
Summary
So to summarize, we began by introducing Machine Learning to you, how Netflix evolved as an entertainment recommender, a hands-on comparison to Netflix’s recommendation model and about Netflix Open Connect, followed by their Open Source Software Initiative.
Thank you for taking the time and patiently reading the article. We look forward to more of such exciting explorations!
As an ending note, we would like to highlight Netflix’s remarkable approach towards art and science as not two separate entities. But as a beautiful unison to create wonders!
