
We all know how to type text on the keyboard. Don’t we?
So, may I challenge you to type that text in your favorite text editor:

This text is challenging to type since it contains:
- typographical signs not directly available on the keyboard,
- hiragana Japanese characters,
- the name of the Japanese capital written with a macron on top of the two letters “o” to comply with the Hepburn romanization standard,
- and finally, the first name Dmitrii written using the Cyrillic alphabet.
No doubt, writing such a sentence on early computers would have been simply impossible. Because computers used limited character sets, unable to let coexist several writing systems. But today such limitations are lifted as we will see in this article.
How do computers store text?
Computers stores characters as numbers. And they use tables to map those numbers to the glyph used to represent them.
For a long time, computers stored each character as a number between 0 and 255 (which fits exactly one byte). But that was far from being sufficient to represent the whole set of characters used in human writing. So, the trick was to use a different correspondence table depending on where in the world you lived.
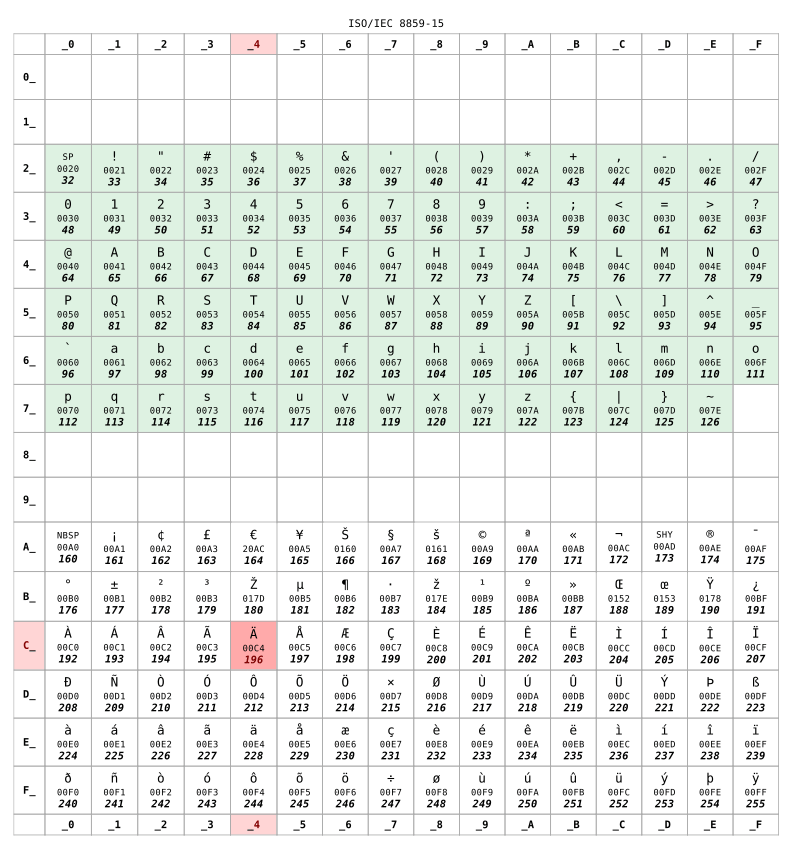
Here is the ISO 8859-15 correspondence table commonly used in France:
But if you lived in Russia, your computer would have probably used the KOI8-R or Windows-1251 encoding instead. Let’s assume that later was used:
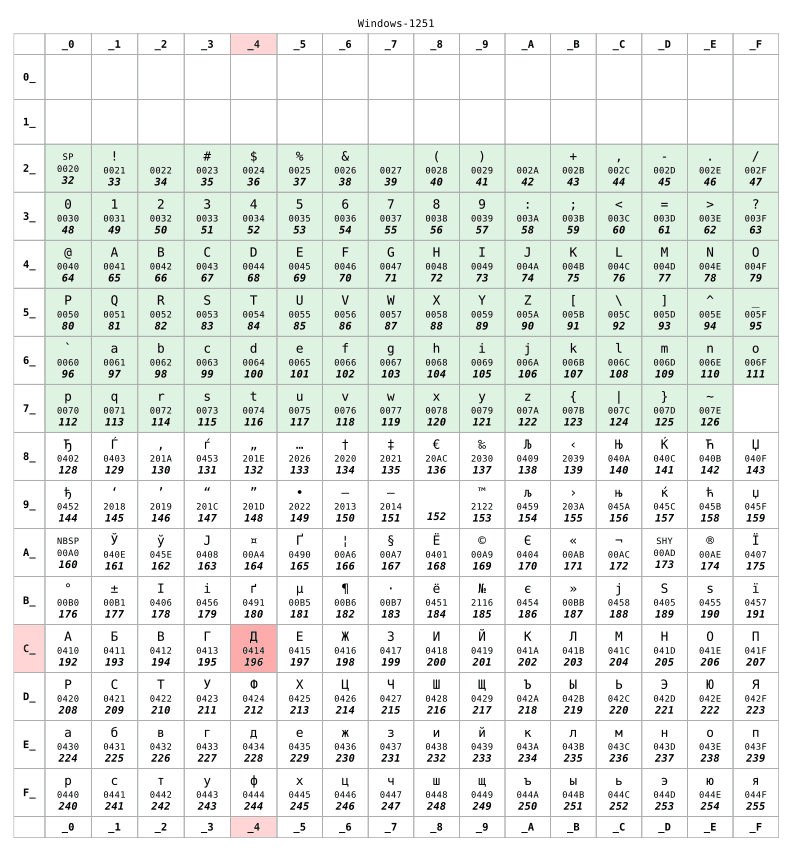
For numbers lower than 128, the two tables are identical. This range is corresponding to the US-ASCII standard, some kind of minimum-compatible set between characters tables. But beyond 128, the two tables are completely different.
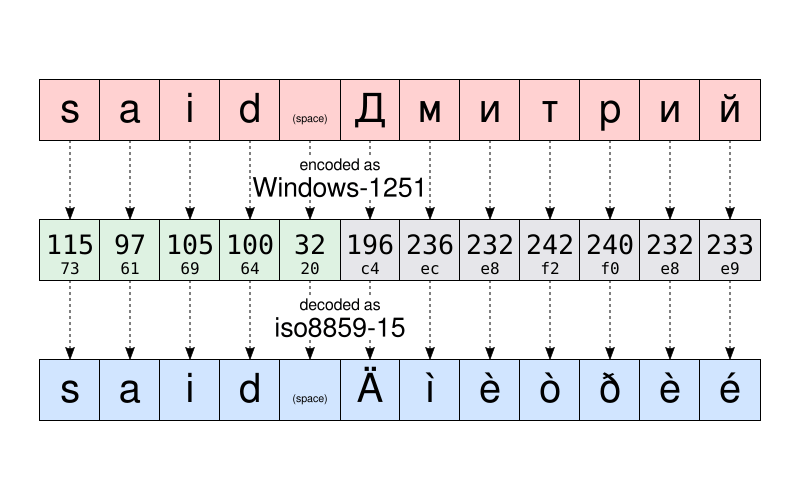
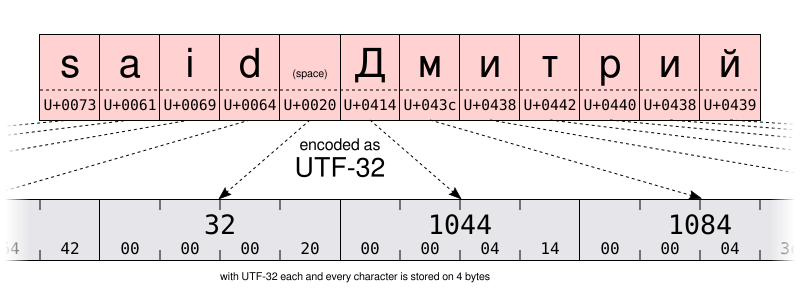
For example, according to Windows-1251, the string “said Дмитрий” is stored as:
115 97 105 100 32 196 236 232 242 240 232 233
To follow a common practice in computer sciences, those twelve numbers can be rewritten using the more compact hexadecimal notation:
73 61 69 64 20 c4 ec e8 f2 f0 e8 e9
If Dmitrii sends me that file, and I open it I might end up seeing that:
said Äìèòðèé
The file appears to be corrupted. But it isn’t. The data— that is the numbers–stored in that file don’t have changed. As I live in France, my computer has assumed the file to be encoded as ISO8859-15. And it displayed the characters of that table corresponding to the data. And not the character of the encoding table used when the text was originally written.
To give you an example, take the character Д. It has the numeric code 196 (c4) according to Windows-1251. The only thing stored in the file is the number 196. But that same number corresponds to Ä according to ISO8859-15. So my computer wrongly believed it was the glyph intended to be displayed.
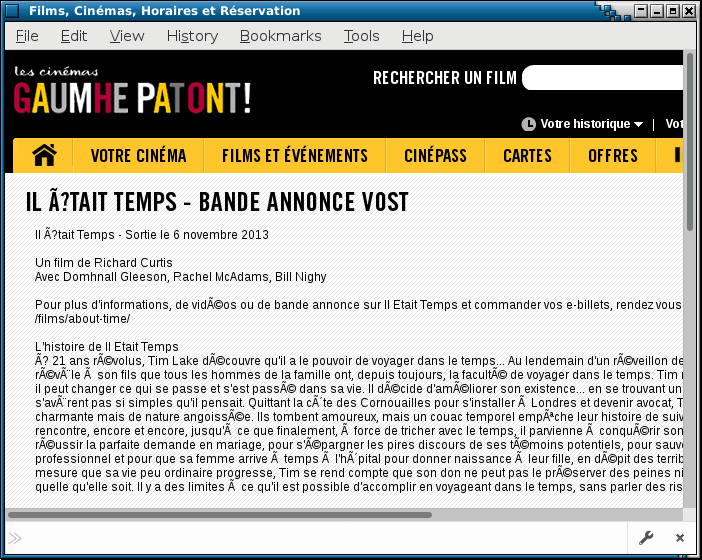
As a side note, you can still occasionally see an illustration of those issues on ill-configured websites or in email send by mail user agents making false assumptions about the character encoding used on the recipient’s computer. Such glitches are sometimes nicknamed mojibake. Hopefully, this is less and less frequent today.
Unicode comes to save to the day
I explained encoding issues when exchanging files between different countries. But things were even worst since the encodings used by different manufacturers for the same country were not always the same. You can understand what I mean if you had to exchange files between Mac and PC in the 80s.
Is it a coincidence or not, the Unicode project started in 1987, led by people of Xerox and … Apple.
The goal of the project was to define a universal character set allowing to simultaneously use any character used in human writing within the same text. The original Unicode project was limited to 65536 different characters (each character being represented using 16 bits— that is two bytes per character). A number that has proven to be insufficient.
So, in 1996 Unicode has been extended to support up to 1 million different code points. Roughly speaking, a “code point” a number that identifies an entry in the Unicode character table. And one core job of the Unicode project is to make an inventory of all letters, symbols, punctuation marks and other characters that are (or were) used worldwide, and to assign to each of them a code point that will uniquely identify that character.
This is a huge project: to give you some idea, the version 10 of Unicode, published in 2017, defines over 136,000 characters covering 139 modern and historic scripts.
With such a large number of possibilities, a basic encoding would require 32 bits (that is 4 bytes) per character. But for text using mainly the characters in the US-ASCII range, 4 bytes per character means 4 times more storage required to save the data and 4 times more bandwidth to transmit them.
So besides the UTF-32 encoding, the Unicode consortium defined the more space-efficient UTF-16 and UTF-8 encodings, using respectively 16 and 8 bits. But how to store over 100,000 different values in only 8 bits? Well, you can’t. But the trick is to use one code value (8 bits in UTF-8, 16 in UTF-16) to store the most frequently used characters. And to use several code values for the least commonly used characters. So UTF-8 and UTF-16 are variable length encoding. Even if this has drawbacks, UTF-8 is a good compromise between space and time efficiency. Not mentioning being backward compatible with most 1-byte pre-Unicode encoding, since UTF-8 was specifically designed so any valid US-ASCII file is also a valid UTF-8 file. In a sense, UTF-8 is a superset of US-ASCII. And today, there is no reason for not using the UTF-8 encoding. Unless of course if you write mostly with languages requiring multi-byte encodings or if you have to deal with legacy systems.
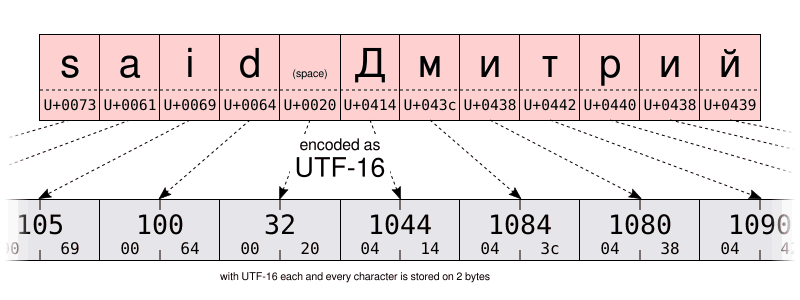
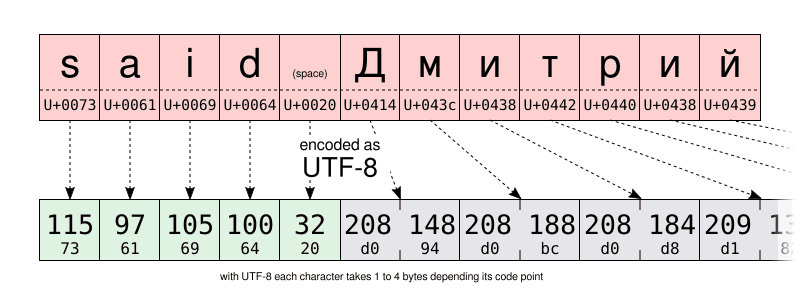
I let you compare the UTF-16 and UTF-8 encoding of the same string on the illustrations below. Pay special attention to the UTF-8 encoding using one byte to store the characters of the Latin alphabet. But using two bytes to store characters of the Cyrillic alphabet. That is twice more space than when storing the same characters using the Windows-1251 Cyrillic encoding.
And how does that help for typing text?
Well… It doesn’t hurt to have some knowledge of the underlying mechanism to understand the capabilities and limitations of your computer. Especially we will talk about Unicode and hexadecimal a little later. But for now… a little bit more history. Just a little bit, I promise…
… just enough to say starting in the 80s, computer keyboard used to have a compose key (sometimes labeled the “multi” key) next to the shift key. By pressing that key, you entered in “compose” mode. And once in that mode, you were able to enter characters not directly available on your keyboard by entering mnemonics instead. For example, in compose mode, typing RO produced the ® character (which is easy to remember as an R inside an O).

It is now a rarity to see the compose key on modern keyboards. Probably because of the domination of PCs that don’t make use of it. But on Linux (and possibly on other systems?) you can emulate the compose key. This is something that can be configured in the GUI on many desktop environments using the “keyboard” control panel: But the exact procedure varies depending on your desktop environment or even depending its version. If you changed that setting, don’t hesitate to use the comment section to share the specific steps you’ve followed on your computer.
As for myself, for now, I will assume you use the default Shift+AltGr combination to emulate the compose key.
So, as a practical example, to enter the LEFT-POINTING DOUBLE ANGLE QUOTATION MARK, you can type Shift+AltGr << (you don’t have to maintain Shift+AltGr pressed when entering the mnemonic). If you managed to do that, I think you should be able to guess by yourself how to enter the RIGHT-POINTING DOUBLE ANGLE QUOTATION MARK.
As another example, try Shift+AltGr --- to produce an EM DASH. For that to work, you have to press the hyphen-minus key on the main keyboard, not the one you will find on your numeric keypad.
Worth mentioning the “compose” key works in a non-GUI environment too. But depending if you use you use X11 or a text-only console, the supported compose key sequence are not the same.
On the console, you can check the list of supported compose key by using the dumpkeys command:
dumpkeys --compose-only
On the GUI, compose key is implemented at Gtk/X11 level. For a list of all mnemonics supported by the Gtk, take a look at that page: https://help.ubuntu.com/community/GtkComposeTable
Is there a way to avoid relying on Gtk for character composition?
Maybe I’m a purist, but I found somewhat unfortunate the compose key support being hard-coded in Gtk. After all, not all GUI applications are using that library. And I cannot add my own mnemonics without re-compiling the Gtk.
Hopefully, there is support for character composition at X11-level too. Formerly, through the venerable X Input Method (XIM).
This will work at lower-level than Gtk-based character composition. But will allow a great amount of flexibility. And will work with many X11 applications.
For example, let’s imagine I just want to add the --> composition to enter the → character (U+2192 RIGHTWARDS ARROW), I would create a ~/.XCompose file containing those lines:
cat > ~/.XCompose << EOT # Load default compose table for the current local include "%L" # Custom definitions <Multi_key> <minus> <minus> <greater> : U2192 # RIGHTWARDS ARROW EOT
Then you can test by starting a new X11 application, forcing libraries to use XIM as input method:
GTK_IM_MODULE="xim" QT_IM_MODULE="xim" xterm
The new compose sequence should be available in the application you launched. I encourage you to learn more about the compose file format by typing man 5 compose.
To make XIM the default input method for all your applications, just add to your ~/.profile file the following two lines. that change will be effective the next time you’ll open a session on your computer:
export GTK_IM_MODULE="xim" export QT_IM_MODULE="xim"
It’s pretty cool, isn’t it? That way you can add all the compose sequences you might want. And there are already a couple of funny ones in the default XIM settings. Try for example to press compose LLAP.
Well, I must mention two drawbacks though. XIM is relatively old and is probably only suitable for those of us who don’t regularly need multi-bytes input methods. Second, when using XIM as your input method, you no longer can enter Unicode characters by their code point using the Ctrl+Shift+u sequence. What? Wait a minute? I didn’t talk about that yet? So let’s do it now:
What if there is no compose key sequence for the character I need?
The compose key is a nice tool to type some characters not available on the keyboard. But the default set of combinations is limited, and switching to XIM and defining a new compose sequence for a character you will need only once in a lifetime can be cumbersome.
Does that prevent you to mix Japanese, Latin and Cyrillic characters in the same text? Certainly not, thanks to Unicode. For example, the name あゆみ is made of:
I mentioned above the official Unicode character names, following the convention to write them in all upper cases. After their name, you will find their Unicode code point, written between parenthesis, as a 16-bit hexadecimal number. Does that remind you something?
Anyway, once you know the code point of a character, you can enter it using the following combination:
- Ctrl+Shift+u, then XXXX (the hexadecimal code point of the character you want) and finally Enter.
As a shorthand, if you don’t release Ctrl+Shift while entering the code point, you won’t have to press Enter.
Unfortunately, that feature is implemented at software library level rather than at X11 level. So the support may be variable among different applications. In LibreOffice, for example, you have to type the code point using the main keyboard. Whereas Gtk-based application will accept entry from the numeric keypad as well.
Finally, when working at the console on my Debian system, there is a similar feature, but requiring instead to press Alt+XXXXX where XXXXX is the code point of the character you want, but written in decimal this time. I wonder if this is Debian-specific or related to the fact I’m using the en_US.UTF-8 locale. If you have more information about that, I would be curious to read you in the comment section!
| GUI | Console | Character |
|---|---|---|
|
Ctrl+Shift+u 3042 Enter |
Alt+12354 |
あ |
|
Ctrl+Shift+u 3086 Enter |
Alt+12422 |
ゆ |
|
Ctrl+Shift+u 307F Enter |
Alt+12415 |
み |
Dead keys
Last but not least, there is a simpler method to enter key combinations that do not rely (necessarily) on the compose key.
Some keys on your keyboard were specifically designed to create a combination of characters. Those are called dead keys. Because when you press them once, nothing seems to happen. But they will silently modify the character produced by the next key you will press. This is a behavior inspired from mechanical typewriter: with them, pressing a dead key imprinted a character, but will not move the carriage. So the next keystroke will imprint another character at the same position. Visually resulting in a combination of the two pressed keys.
We use that a lot in French. For example, to enter the letter “ë” I have to press the ¨ dead key followed by the e key. Similarly, Spanish people have the ~ dead key on their keyboard. And on the keyboard layout for Nordic languages, you can find the ° key. And I could continue that list for a very long time.
Obviously, not all dead keys are available on all keyboard. I fact, most dead keys are NOT available on your keyboard. For example, I assume very few of you— if any— have a dead key ¯ to enter the macron (“flat accent”) used to write Tōkyō.
For those dead keys that are not directly available on your keyboard, you need to resort to other solutions. The good news is we’ve already used those techniques. But this time we will use them to emulate dead keys. Not “ordinary” keys.
So, a first option could be to generate the macron dead key by using Compose - (the hyphen-minus key available on your keyboard). Nothing appears. But if after that you press the o key it will finally produce “ō”.
The list of dead keys that Gtk can produce using the compose mode can be found here.
A different solution would use the Unicode COMBINING MACRON (U+0304) character. Followed by the letter o. I will leave the details up to you. But if you’re curious, you may discover this leads to a very subtlely different result, rather than really producing a LATIN SMALL LETTER O WITH MACRON. And if I wrote the end of the previous sentence in all uppercase, this is a hint guiding you toward a method to enter ō with fewer keystrokes than by using a Unicode combining character… But I let that to your sagacity.
Your turn to practice!
So, did you get it all? Does that work on your computer? It’s your turn to try that: using the clues given above, and a little bit of practice, now you can enter the text of the challenge given in the beginning of this article. Do it, then copy-paste your text in the comment section below as proof of your success.
There is nothing to win, except maybe the satisfaction of impressing your peers!
