
rga, called ripgrep-all, is an excellent tool that allows you to search almost all files for a text pattern. While the OG grep command is limited to plaintext files, rga can search for text in a wide range of file types such as PDF, e-Books, Word documents, zip, tar, and even embedded subtitles.
What is it exactly?
The grep command is used for searching for text-based patterns in files. It actually means global regex pattern. You can not only search for simple words, but can also specify that the word should be the first word in a line, at the end of a line, or a specific word should come before it. That is why grep is so powerful, because it uses regex (regular expressions).
There is also a limitation on grep, kind of. You can only use grep to search for patterns in a plaintext file. That means you can not search for patterns in a PDF document, in a compressed tar/zip archive, nor in a database like SQLite.
Now imagine having the powerful search that grep offers, but for other file types too. That is rga, or ripgrep-all, whatever you might call it.
It is ripgrep, but with added functionality. We also have a tutorial covering ripgrep, in case you are interested in it.
How to install ripgrep-all
Arch Linux users can easily install ripgrep-all using the following command:
sudo pacman -S ripgrep-allThe Nix package manger has ripgrep-all packaged and for that, use the following command:
nix-env -iA nixpkgs.ripgrep-allMac users can should the homebrew package manager like so:
brew install ripgrep-allDebian/Ubuntu users
At the moment, ripgrep-all is neither available in Debian’s first-party repositories nor Ubuntu’s repositories. Fret not, that doesn’t mean it is unobtainium.
On any other Debian based operating system (Ubuntu and its derivatives too), install the necessary dependencies first:
sudo apt-get install ripgrep pandoc poppler-utils ffmpegOnce those are installed, visit this page that contains the installer. Find the file that has the “x86_64-unknown-linux-musl” suffix. Download and extract it.
That tar archive contains two necessary binary executable files. They are “rga” and “rga-preproc”.
Copy them to the “~/.local/bin” directory. In most cases, this directory will exist, but in case you do not have it, create it using the following command:
mkdir -p $HOME/.local/binFinally, add the following lines to your “~/.bashrc” file:
if ! [[ $PATH =~ "$HOME/.local/bin" ]]; then
PATH="$HOME/.local/bin:$PATH"
fiNow, close and re-open the terminal to make the changes made in “~/.bashrc” effective. With that, ripgrep-all is installed.
Using ripgrep-all
ripgrep-all is the name of the project, not the command name, the command name is rga.
The rga utility supports the following file extensions:
- media:
.mkv,.mp4,.avi - documents:
.epub,.odt,.docx,.fb2,.ipynb,.pdf - compressed archives:
.zip,.tar,.tgz,.tbz,.tbz2,.gz,.bz2,.xz,.zst - databases:
.db,.db3,.sqlite,.sqlite3 - images (OCR):
.jpg,.png
You might be familiar with grep, but let us look at some examples nonetheless. This time, with rga instead of grep.
Before you proceed further, please take a look at the directory hierarchy given down below:
.
├── my_demo_db.sqlite3
├── my_demo_document.odt
└── TLCL-19.01.pdf.zipCase insensitive and case sensitive search
The simplest pattern matching is to search for a word in a file. Let us try that. I will use the rga command to perform a case sensitive search for the words “red hat enterprise linux” for all files in current directory.
While grep has case sensitivity turned on by default, with rga, the -s option needs to be used.
rga -s 'red hat enterprise linux'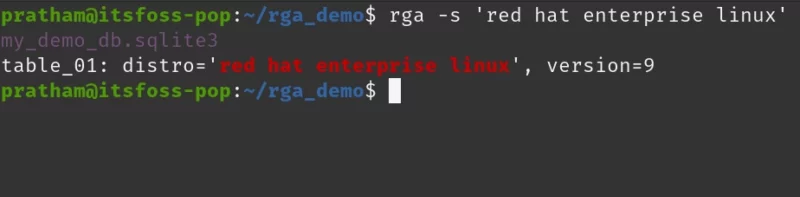
As you can see, with a case sensitive search, I only got the result from a sqlite3 database file. Now, let us try a case insensitive search using the -i option and see what results we get.
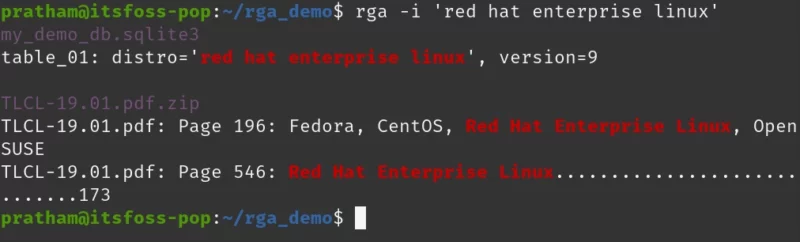
rga -i 'red hat enterprise linux'Ah, this time we also got a match from the The Linux Command Line book by William Shotts.
Inverse match
With grep, and by extension, with ripgrep-all, you can do an inverse match. Which means, “Show only lines that do NOT have this pattern”.
The option for that is -v and that needs to be present immediately before the pattern.
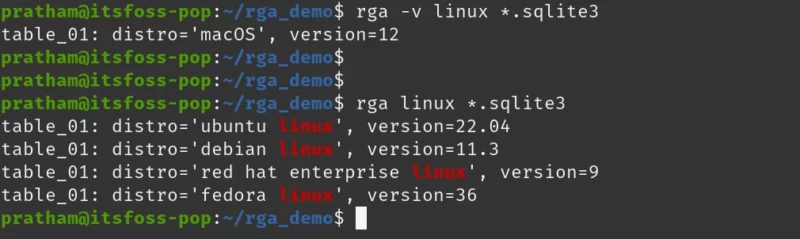
rga -v linux *.sqlite3 AND rga linux *sqlite3Hey! Hold on. That isn’t Linux!
This time I only selected the database file, that is because every other file has a lot of lines that do not contain the word ‘linux’ in them.
And as you can see, the first command’s output does not have the word ‘linux’ in it. The second command is only to demonstrate that ‘linux’ is present in the database.
Contextual search
One thing I love about rga’s ability to search databases, in particular, is that it can not only search for your match but also provide relevant context (when asked). Although search in databases is not special, it is always a “Oh wow, it can do that?!” moment.
A contextual search is performed using the following three options:
-A: show context after the matched line-B: show context before the matched line-C: show context before and after the matched line
If this sounds confusing, fret not. I will discuss each option to help you understand it better.
Using the -C option
To show you what I am talking about, let us take a look at the following command and it’s output. This is an example of using the -C option.
rga -C 2 'red hat enterprise linux'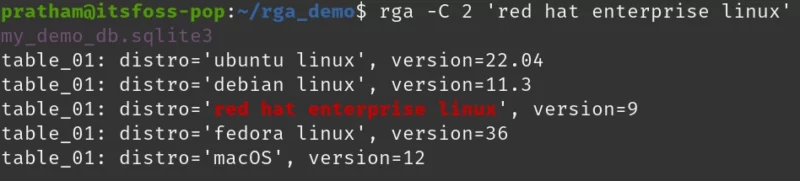
As you can see, not only I get the match from my database file, but I can also see the rows that are chronologically before the match and also rows that are after the match. This did not randomly jumble my rows, which is quite nice because I did not use keys to number each row.
You might be wondering if something is wrong. I specified ‘2’, but only got ‘1’ line after. Well, that is because there is no row after the ‘fedora linux’ row in my database. :)
Using the -A option
To better understand the use of -A option, let us have a look at an example.
rga -A 2 Yours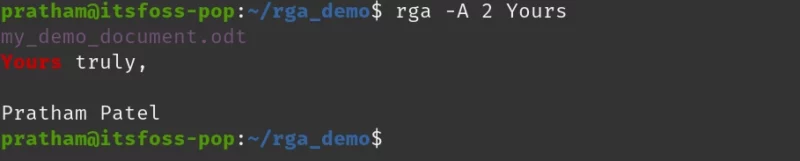
I see that is a letter of some sort… Makes me wonder what was in the body.
Using the -B option
I think that document is incomplete… Let us get a context of the lines that are above it.
To see the previous lines, we need to use the -B option.
rga -B 6 Yours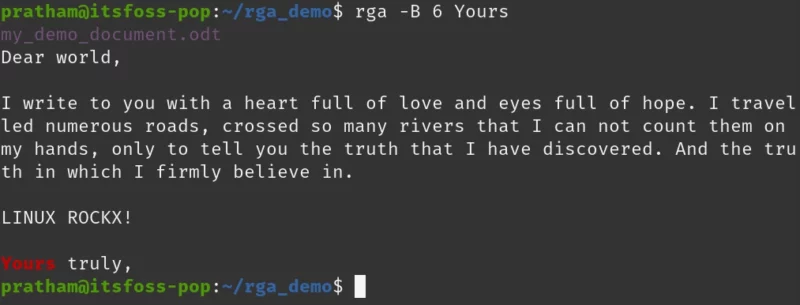
As you can see, I asked “Show me the 6 lines that come before my matched line” and I got this in the output. Quite handy for some situations, don’t you think?
Multi-threaded search
Since ripgrep-all is a wrapper around ripgrep, you can make use of various options that LinuxHandbook has already covered.
One of those options is multi-threading. By default ripgrep chooses the thread count based on heuristics. And so, ripgrep-all does the same too.
That doesn’t mean you can not specify them yourself! :)
The option to do so is -j. Use it like so:
rga -j NUM-OF-THREADSThere isn’t a practical example to show this reliably, so I will leave this for you to test it yourself ;)
Caching
One of the main selling points of rga, besides supporting the vast number of file extensions, is that it efficiently caches data.
As a default, depending on the OS, the following directories will store the cache generated by rga:
- Linux:
~/.cache/rga - macOS:
~/Library/Caches/rga
I will first run the following command to remove my cache:
rm -rf ~/.cache/rgaOnce the cache is cleared, I will run a simple query 2 times. I expect to see a performance improvement the second time.
time rga -i linux > /dev/null
time rga --rga-no-cache -i linux > /dev/null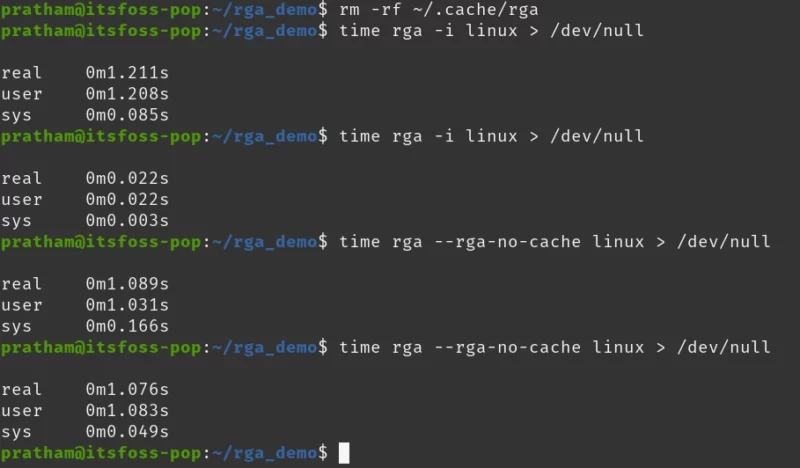
I deliberately chose the pattern ‘linux’ as it is occurring a lot of times in ‘The Linux Command Line’ book’s PDF and also in my ‘.odt’ document as well as my database file. To check speed, I don’t need to check the output, so that is redirected to the ‘/dev/null’ file.
I see that the first time the command is ran, it does not have a cache. But the second time running the same command yields a faster run.
In the end, I also use the –rga-no-cache option, to disable the use of the cache, even if it is present. The result is similar to the first run of rga command.
Conclusion
rga is the Swiss Army Knife of grep. It is one tool that can be used for almost any kind of file and it behaves similarly to grep, at least with the regex, less so with the options.
But all in all, rga is one of the tools that I recommend you use. Do comment and share your experience/thoughts!
