
Even if you use the Linux command line moderately, you must have come across the grep command.
Grep is used to search for a pattern in a text file. It can do crazy powerful things, like search for new lines, search for lines where there are no uppercase characters, search for lines where the initial character is a number, and much, much more. Check out some common grep command examples if you are interested.
But grep works only on plain text files. It won’t work on PDF files because they are binary files.
This is where pdfgrep comes into the picture. It works like grep for PDF files. Let us have a look at that.
Meet pdfgrep: grep like regex search for PDF files
pdfgrep tries to be compatible with GNU Grep, where it makes sense. Several of your favorite grep options are supported (such as -r, -i, -n or -c). You can use to search for text inside the contents of PDF files.
Though it doesn’t come pre-installed like grep, it is available in the repositories of most Linux distributions.
You can use your distribution’s package manager to install this awesome tool.
For users of Ubuntu and Debian-based distributions, use the apt command:
sudo apt install pdfgrepFor Red Hat and Fedora, you can use the dnf command:
sudo dnf install pdfgrepBtw, do you run Arch? You can use the pacman command:
sudo pacman -S pdfgrepUsing pdfgrep command
Now that pdfgrep is installed let me show you how to use it in most common scenarios.
If you have any experience with grep, then most of the options will feel familiar to you.
To demonstrate, I will be using The Linux Command Line PDF book, written by William Shotts. It’s one of the few Linux books that are legally available for free.
The syntax for pdfgrep is as follows:
pdfgrep [PATTERN] [FILE.pdf]Normal search
Let’s try doing a basic search for the text ‘xdg’ in the PDF file.
pdfgrep xdg TLCL-19.01.pdf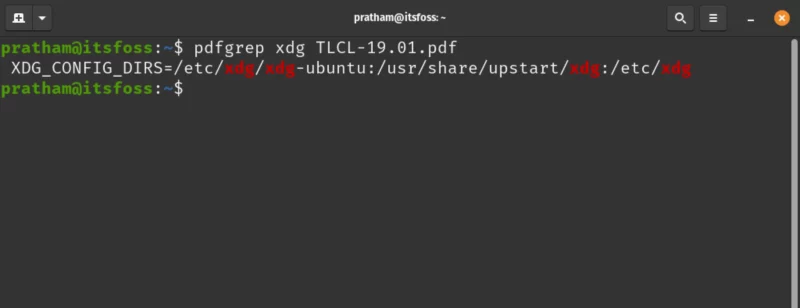
This resulted in only one match… But a match nonetheless!
Case insensitive search
Most of the time, the term ‘xdg’ is used with capitalized alphabetical characters. So, let’s try doing a case-insensitive search. For a case insensitive search, I will use the –ignore-case option.
You can also use the shorter alternative, which is -i.
pdfgrep --ignore-case xdg TLCL-19.01.pdf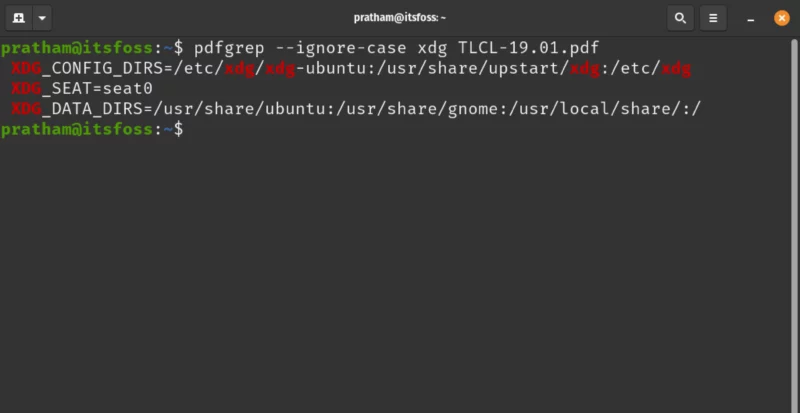
As you can see, I got more matches after turning on case insensitive searching.
Get a count of all matches
Sometimes, the user wants to know how many matches were found of the word. Let’s see how many times the word ‘Linux’ is mentioned (with case insensitive matching).
The option to use in this scenario is –count (or -c for short).
pdfgrep --ignore-case linux TLCL-19.01.pdf --count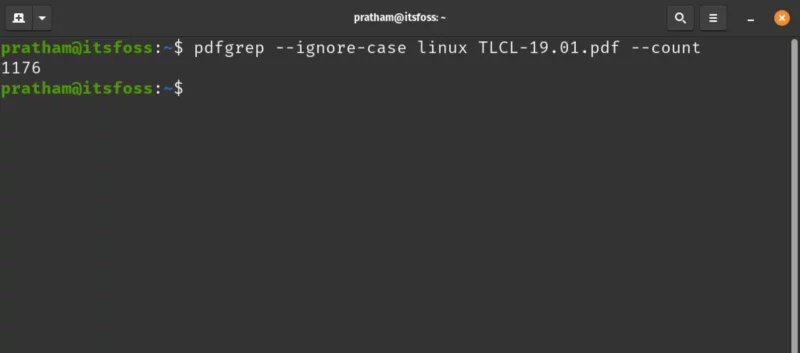
Woah! Linux was mentioned 1200 times in this book… That was unexpected.
Show page number
Regular text files are giant monolithic files. There are no pages. But a PDF file has pages. So, you can see where the pattern was found and on which page. Use the –page-number option to show the page number where the pattern was matched. You can also use the -n option as a shorter alternative.
Let us see how it works with an example. I want to see the pages where the word ‘awk’ matches. I added a space at the end of the pattern to prevent matching with words like ‘awkward’, getting unintentional matches would be awkward. Instead of escaping space with a backslash, you can also enclose it in single quotes ‘awk ‘.
pdfgrep --page-number --ignore-case awk\ TLCL-19.01.pdf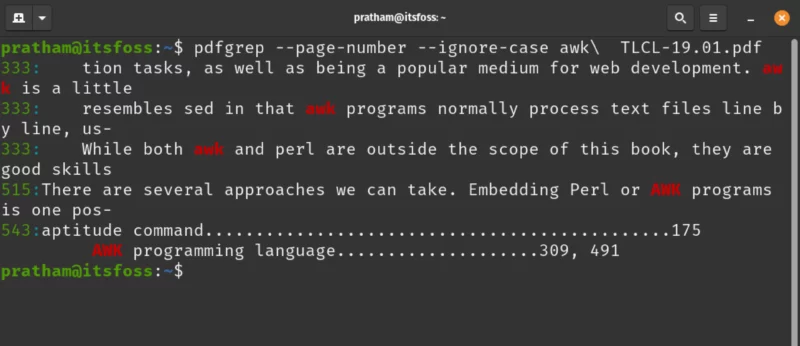
The word ‘awk’ was found twice on page number 333, once on page 515 and once again on page 543 in the PDF file.
Show match count per page
Do you want to know how many matches were found on which page instead of showing the matches themselves? If you said yes, well it is your lucky day!
Using the –page-count option does exactly that. As a shorter alternative, you use the -p option. When you provide this option to pdfgrep, it is assumed that you requested -n as well.
Let’s take a look at how the output looks. For this example, I will see where the ln command is used in the book.
pdfgrep --page-count ln\ TLCL-19.01.pdf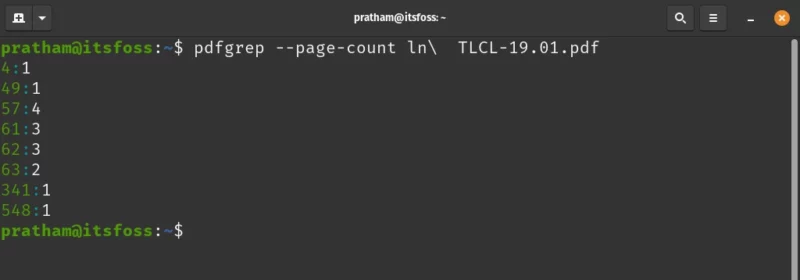
The output is in the form of ‘page number: matches’. This means, on page number 4, the command (or rather “pattern”) was found only once. But on page number 57, pdfgrep found 4 matches.
Get some context
When the number of matches found is quite big, it is nice to have some context. For that, pdfgrep provides some options.
- –after-context NUM: Print NUM of lines that come after the matching lines (or use
-A) - –before-context NUM: Print NUM of lines that are before the matching lines (or use
-B) - –context NUM: Print NUM of lines that are before and come after the matching lines (or use
-C)
Let’s find ‘XDG’ in the PDF file, but this time, with a little more context ( ͡❛ ͜ʖ ͡❛)
Context after matches
Using the –after-context option along with a number, I can see which lines come after the line(s) that match. Below is an example of how it looks.
pdfgrep --after-context 2 XDG TLCL-19.01.pdf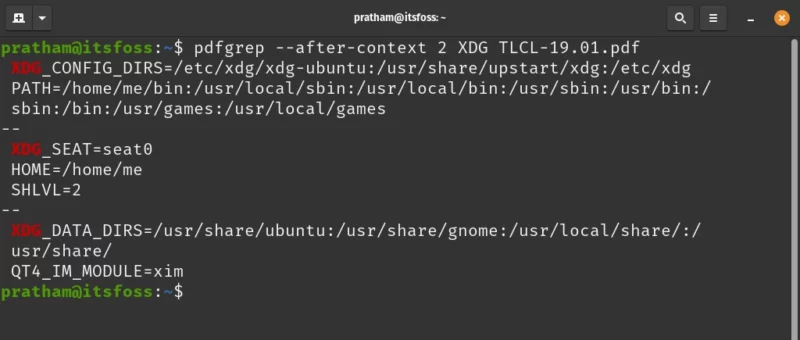
Context before matches
Same thing can be done for scenarios when you need to know what lines are present before the line that matches. In that case, use the –before-context option, along with a number. Below is an example demonstrating usage of this option.
pdfgrep --before-context 2 XDG TLCL-19.01.pdf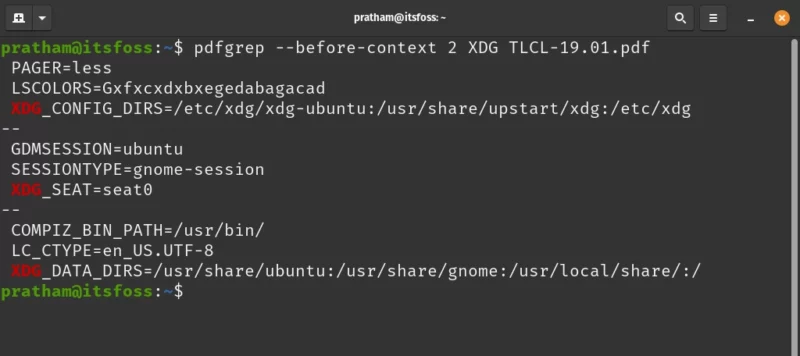
Context around matches
If you want to see which lines are present before and come after the line that matched, use the –context option and also provide a number. Below is an example.
pdfgrep --context 2 XDG TLCL-19.01.pdf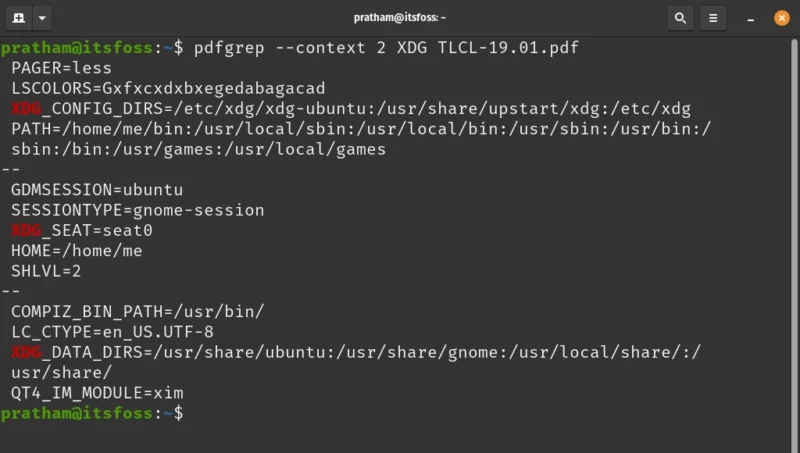
Caching
A PDF file consists of images as well as text. When you have a large PDF file, it might take some time to skip other media, extract text and then “grep” it. Doing it often and waiting every time can get frustrating.
For that reason, the –cache option exists. It caches the rendered text to speed up grep-ing. This is especially noticeable on large files.
pdfgrep --cache --ignore-case grep TLCL-19.01.pdf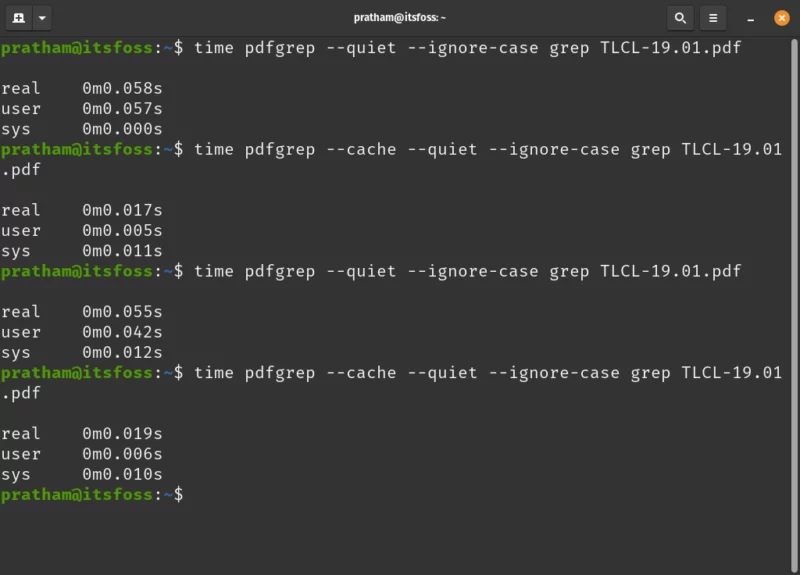
While not the be-all and end-all, I carried out a search 4 times. Twice with cache enable and twice without cache enable. To show the speed difference, I used the time command. Look closely at the time indicated by ‘real’ value.
As you can see, the commands that include –cache option were completed faster than the ones that didn’t include it.
Additionally, I suppressed the output using the –quiet option for faster completion.
Password protected PDF files
Yes, pdfgrep supports grep-ing even password-protected files. All you have to do is use the –password option, followed by the password.
I do not have a password-protected file to demonstrate with, but you can use this option in the following manner:
pdfgrep --password [PASSWORD] [PATTERN] [FILE.pdf]Conclusion
pdfgrep is a very handy tool if you are dealing with PDF files and want the functionality of ‘grep’, but for PDF files. A reason why I like pdfgrep is that it tries to be compatible with GNU Grep.
Give it a try and let me know what you think of pdfgrep.
