

If you are stuck to the Linux terminal, say on a server, how do you download a file from the terminal?
There is no download command in Linux but there are a couple of Linux commands for downloading file.
In this terminal trick, you’ll learn two ways to download files using the command line in Linux.
I am using Ubuntu here but apart from the installation, the rest of the commands are equally valid for all other Linux distributions.
Download files from Linux terminal using wget command
wget is perhaps the most used command line download manager for Linux and UNIX-like systems. You can download a single file, multiple files, an entire directory, or even an entire website using wget.
wget is non-interactive and can easily work in the background. This means you can easily use it in scripts or even build tools like uGet download manager.
Let’s see how to use wget to download files from terminal.
Installing wget
Most Linux distributions come with wget preinstalled. It is also available in the repository of most distributions and you can easily install it using your distribution’s package manager.
On Ubuntu and Debian based distributions, you can use the apt package manager command:
sudo apt install wgetDownload a file or webpage using wget
You just need to provide the URL of the file or webpage. It will download the file with its original name in the directory you are in.
wget URL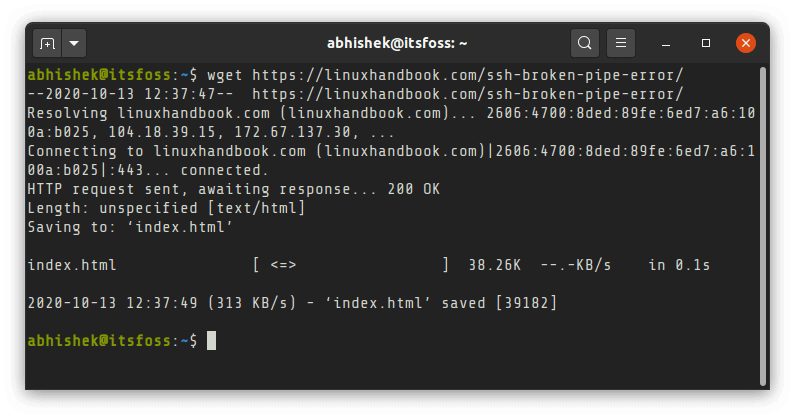
To download multiple files, you’ll have to save their URLs in a text file and provide that text file as input to wget like this:
wget -i download_files.txtDownload files with a different name using wget
You’ll notice that a webpage is almost always saved as index.html with wget. It will be a good idea to provide custom name to downloaded file.
You can use the -O (uppercase O) option to provide the output filename while downloading.
wget -O filename URL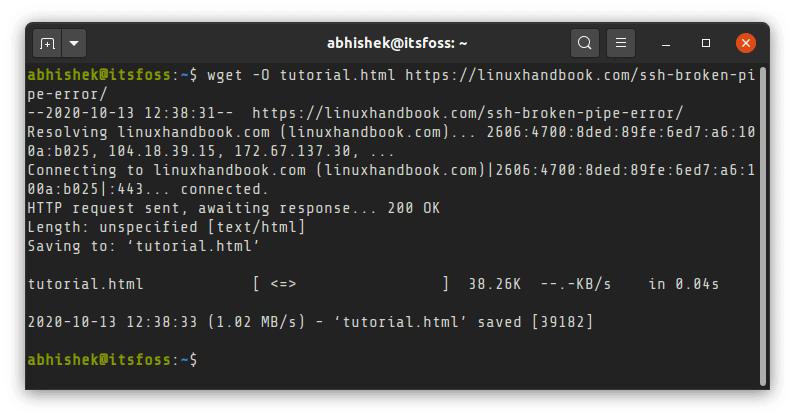
Download a folder using wget
Suppose you are browsing an FTP server and you need to download an entire directory, you can use the recursive option
wget -r ftp://server-address.com/directoryDownload an entire website using wget
Yes, you can totally do that. You can mirror an entire website with wget. By downloading an entire website I mean the entire public facing website structure.
While you can use the mirror option -m directly, it will be a good idea add:
- –convert-links : links are converted so that internal links are pointed to downloaded resource instead of web
- –page-requisites: downloads additional things like style sheets so that the pages look better offline
wget -m --convert-links --page-requisites website_address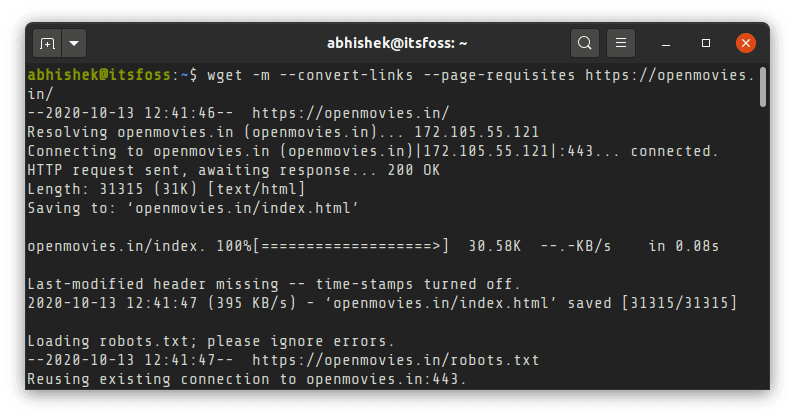
Bonus Tip: Resume incomplete downloads
If you aborted the download by pressing C for some reasons, you can resume the previous download with option -c.
wget -c Download files from Linux command line using curl
Like wget, curl is also one of the most popular commands to download files in Linux terminal. There are so many ways to use curl extensively but I’ll focus on only the simple downloading here.
Installing curl
Though curl doesn’t come preinstalled, it is available in the official repositories of most distributions. You can use your distribution’s package manager to install it.
To install curl on Ubuntu and other Debian based distributions, use the following command:
sudo apt install curlDownload files or webpage using curl
If you use curl without any option with a URL, it will read the file and print it on the terminal screen.
To download a file using curl command in Linux terminal, you’ll have to use the -O (uppercase O) option:
curl -O URL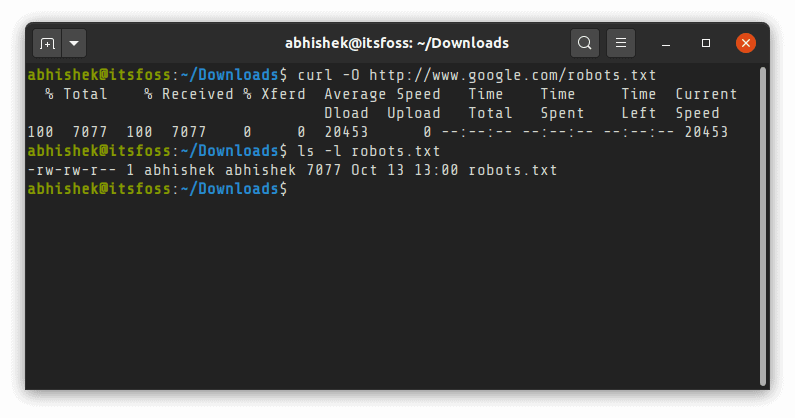
It is simpler to download multiple files in Linux with curl. You just have to specify multiple URLs:
curl -O URL1 URL2 URL3Keep in mind that curl is not as simple as wget. While wget saves webpages as index.html, curl will complain of remote file not having a name for webpages. You’ll have to save it with a custom name as described in the next section.
Download files with a different name
It could be confusing but to provide a custom name for the downloaded file (instead of the original source name), you’ll have to use -o (lowercase O) option:
curl -o filename URL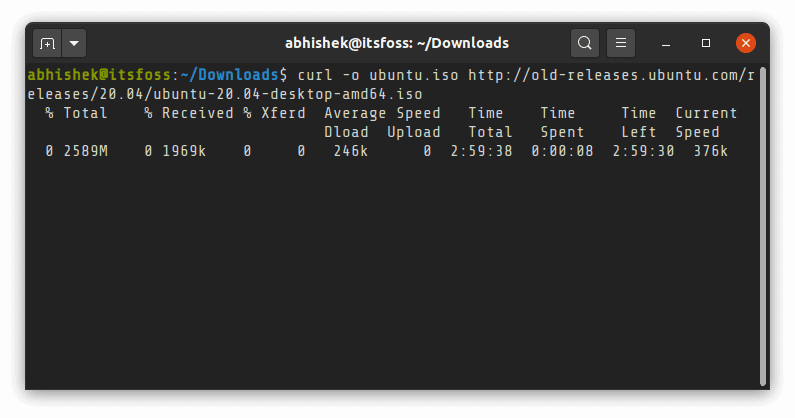
Some times, curl wouldn’t just download the file as you expect it to. You’ll have to use option -L (for location) to download it correctly. This is because some times the links redirect to some other link and with option -L, it follows the final link.
Pause and resume download with curl
Like wget, you can also resume a paused download using curl with option -c:
curl -C URLConclusion
As always, there are multiple ways to do the same thing in Linux. Downloading files from the terminal is no different.
wget and curl are just two of the most popular commands for downloading files in Linux. There are more such command line tools. Terminal based web-browsers like elinks, w3m etc can also be used for downloading files in command line.
Personally, for a simple download, I prefer using wget over curl. It is simpler and less confusing because you may have a difficult time figuring out why curl could not download a file in the expected format.
Your feedback and suggestions are welcome.
If this helped you, consider supporting It's FOSS
It's FOSS has been helping people use Linux for the past 14 years. Help us stay independent from big tech. Become a Plus member, enjoy ad-free reading and get 5 eBooks.
