

When you are new to Linux, you’ll often come across advice to never run sudo rm -rf /. There are so many memes in the Linux world around sudo rm -rf.

But it seems that there are some confusions around it. In the tutorial on cleaning Ubuntu to make free space, I advised running some command that involved sudo and rm -rf. An It’s FOSS reader asked me why I am advising that if sudo rm -rf is a dangerous Linux command that should not be run.
And thus I thought of writing this chapter of Linux jargon buster and clear the misconceptions.
sudo rm -rf: what does it do?
Let’s learn things in steps.
The rm command is used for removing files and directories in Linux command line.
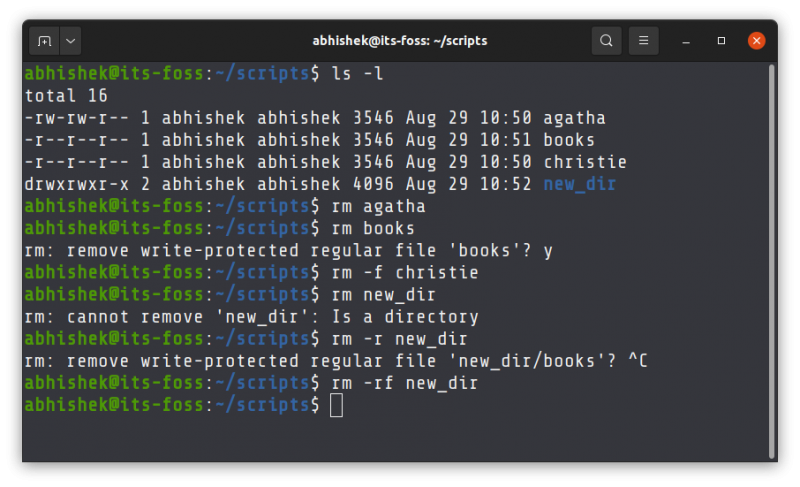
abhishek@its-foss:$ rm agatha
abhishek@its-foss:$But some files will not be removed immediate because of read only file permissions. They have to be forced delete with the option -f.
abhishek@its-foss:$ rm books
rm: remove write-protected regular file 'books'? y
abhishek@its-foss:$ rm -f christie
abhishek@its-foss:$However, rm command cannot be used to delete directories (folders) directly. You have to use the recursive option -r with the rm command.
abhishek@its-foss:$ rm new_dir
rm: cannot remove 'new_dir': Is a directoryAnd thus ultimately, rm -rf command means recursively force delete the given directory.
abhishek@its-foss:~$ rm -r new_dir
rm: remove write-protected regular file 'new_dir/books'? ^C
abhishek@its-foss:$ rm -rf new_dir
abhishek@its-foss:$Here’s a screenshot of all the above commands:
If you add sudo to the rm -rf command, you are deleting files with root power. That means you could delete system files owned by root user.
So, sudo rm -rf is a dangerous Linux command?
Well, any command that deletes something could be dangerous if you are not sure of what you are deleting.
Consider rm -rf command as a knife. Is knife a dangerous thing? Possibly. If you cut vegetables with the knife, it’s good. If you cut your fingers with the knife, it is bad, of course.
The same goes for rm -rf command. It is not dangerous in itself. It is used for deleting files after all. But if you use it to delete important files unknowingly, then it is a problem.
Now coming to ‘sudo rm -rf /’.
You know that with sudo, you run a command as root, which allows you to make any changes to the system.
/ is the symbol for the root directory. /var means the var directory under root. /var/log/apt means apt directory under log, under root.
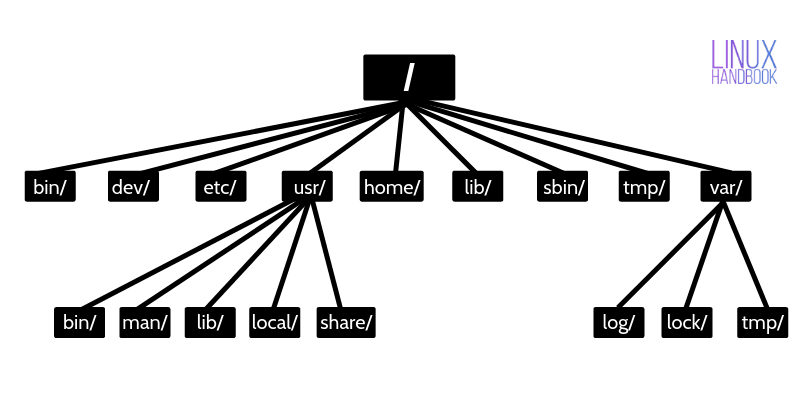
As per Linux directory hierarchy, everything in a Linux file system starts at root. If you delete root, you are basically removing all the files of your system.
And this is why it is advised to not run sudo rm -rf / command because you’ll wipe out your entire Linux system.
Please note that in some cases, you could be running a command like ‘sudo rm -rf /var/log/apt’ which could be fine. Again, you have to pay attention on what you are deleting, the same as you have to pay attention on what you are cutting with a knife.
I play with danger: what if I run sudo rm -rf / to see what happens?
Most Linux distributions provide a failsafe protection against accidentally deleting the root directory.
abhishek@test-vm:~$ sudo rm -rf /
[sudo] password for abhishek:
rm: it is dangerous to operate recursively on '/'
rm: use --no-preserve-root to override this failsafeI mean it is human to make typos and if you accidentally typed “/ var/log/apt” instead of “/var/log/apt” (a space between / and var meaning that you are providing / and var directories to for deletion), you’ll be deleting the root directory.
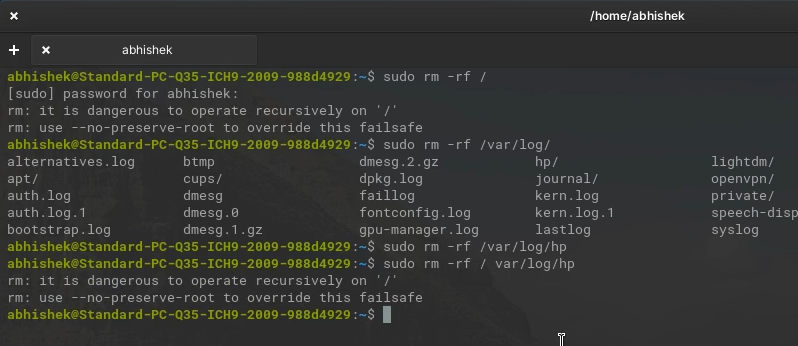
That’s quite good. Your Linux system takes care of such accidents.
Now, what if you are hell-bent on destroying your system with sudo rm -rf /? You’ll have to use It will ask you to use –no-preserve-root with it.
No, please do not do that on your own. Let me show it to you.
So, I have elementary OS running in a virtual machine. I run sudo rm -rf / --no-preserve-root and you can see the lights going out literally in the video below (around 1 minute).
Clear or still confused?
Linux has an active community where most people try to help new users. Most people because there are some evil trolls lurking to mess with the new users. They will often suggest running rm -rf / for the simplest of the problems faced by beginners. These idiots get some sort of supremacist satisfaction I think for such evil acts. I ban them immediately from the forums and groups I administer.
I also recommend going through some of the other potentially harmful Linux commands that are often used to trick new users.
 Abhishek Prakash
Abhishek Prakash
I hope this article made things clearer for you. It’s possible that you still have some confusion, especially because it involves root, file permissions and other things new users might not be familiar with. If that’s the case, please let me know your doubts in the comment section and I’ll try to clear them.
In the end, remember. Don’t drink and root. Stay safe while running your Linux system :)

