

Ollama is a free and open-source project that lets you run various open source LLMs locally.
Whether you want to utilize an open-source LLM like Codestral for code generation or LLaMa 3 for a ChatGPT alternative, it is possible with Ollama.
But those are the end goals that you can achieve locally with Ollama on your system. What do you need to know to make that happen? How do you do all that?
In this article, I'll provide all the essential information about Ollama.
What is Ollama?
Ollama is a free and open-source tool that lets anyone run open LLMs locally on your system. It supports Linux (Systemd-powered distros), Windows, and macOS (Apple Silicon).
It is a command-line interface (CLI) tool that lets you conveniently download LLMs and run it locally and privately. With a couple of commands you can download models like Llama 3, Mixtral, and more.
Think of it like Docker. With Docker, you download various images from a central repository and run them in a container. Similarly, using Ollama, you download various open source LLMs and then run them in your terminal.
What are the system requirements?
To be able to utilize Ollama, you need a system that is capable of running the AI models.
For starters, you require a GPU to run things. With a CPU (or integrated GPU), it will be a painfully slow experience. So, it is not recommended.
Next, you need to ensure that you have a GPU from Nvidia/AMD with compute capability of 5 at the very least. Some popular supported GPUs include:
- NVIDIA RTX 40x0 series, NVIDIA RTX 30x0 series, GTX 1650 Ti, GTX 750 Ti, GTX 750
- AMD Vega 64, AMD Radeon RX 6000 series, AMD Radeon RX 7000 series
You can find the complete list of supported GPUs in Ollama's official documentation.
Does Ollama work With TPU or NPU?
Unfortunately, Ollama does not officially support TPUs or NPUs currently.
If you are curious, TPU (Tensor Processing Unit) is Google's custom-made integrated circuit (IC) tailored for machine learning workflows. It may not be the most powerful solution to run machine learning models, but it makes things convenient/flexible and affordable in some cases with Google Cloud.
NPU is the Neural Processing Unit, which is specifically used for AI-related tasks. Think of them as GPU but for AI.
There are projects like ezrknpu that try to provide some LLM models that run on NPU. Abhishek tested it on ArmSoM Sige7 but for now, Ollama doesn't utilize NPU, it needs GPU.
Can Ollama run on CPU only?
Yes, it can but it should be avoided. Ollama is designed to use the Nvidia or AMD GPUs. It does not recognize the integrated Intel GPU. While you may go ahead and run Ollama on CPU only, the performance will be way below par even when your 16 core processor is maxed out.
How to install Ollama?
If you want to get started with Ollama on Linux, we have a fantastic tutorial that you can follow:
 Abhishek Prakash
Abhishek Prakash
Ollama models
Ollama focuses on providing you access to open models, some of which allow for commercial usage and some may not.
The models are hosted by Ollama, which you need to download using the pull command like this:
ollama pull codestral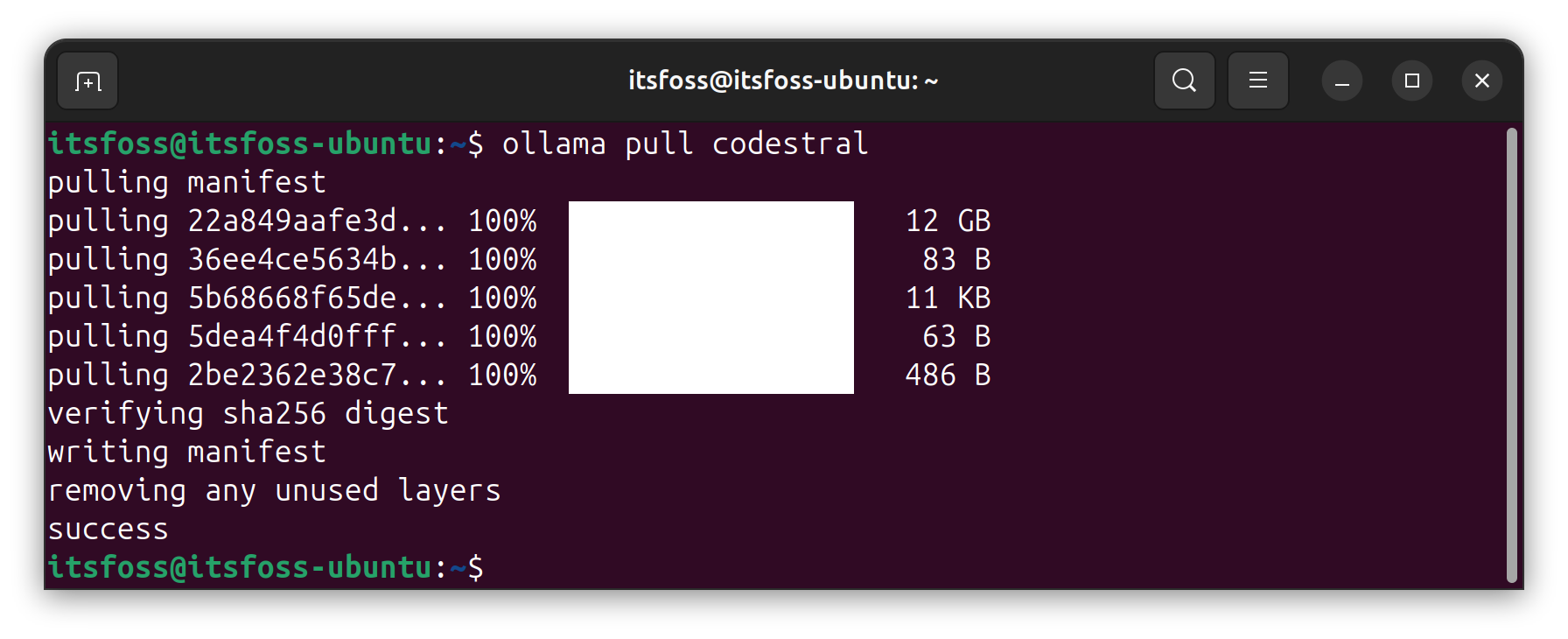
Your data is not trained for the LLMs as it works locally on your device. However, if you like, you can deploy it as a service to interact with your software application. You can refer to its GitHub repo to find out more about it.
Some of the useful models available with Ollama include:
- llama 3: A family of open models developed by Meta Inc with instruction-tuned and pre-trained variants
- gemma: Lightweight open models developed by Google DeepMind and inspired by Google Gemini.
- Mistral: A powerful open-source model available under Apache 2.0 license
- Codestral: Mistral's AI model under a non-production license, trained with 80+ programming languages
You can find all the LLMs available listed in the Ollama library portal. You can check the details and pull it to use it on your device.
If you do not need a model, you can simply remove it using this command on Linux:
ollama rm codestral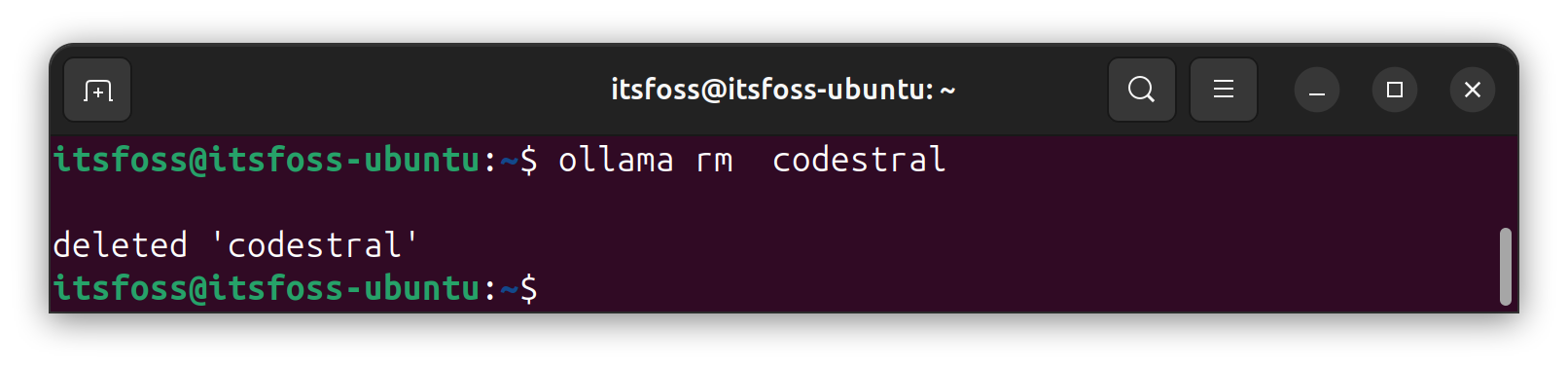
I would recommend reading more on Ollama commands:

Where are the models stored?
Sometimes users report that even after using the remove command, the storage space is not freed up, meaning the deletion was not successful.
So, in those cases, or maybe if you want to delete multiple models using the graphical user interface (GUI) or the file manager, you need to know the storage location. Here is the default storage path for the models downloaded:
- Linux:
/usr/share/ollama/.ollama/models - Windows:
C:\Users\%username%\.ollama\models - macOS:
~/.ollama/models
How to stop Ollama?
For Windows/macOS, you can head to the system tray icon in the bottom-right or top-right (depending on your position of the taskbar) and click on "Exit Ollama".
With Linux, you need to enter the following command to stop Ollama process from running in the background:
sudo systemctl stop ollamaHow to get a GUI for Ollama?
Since it is primarily a CLI tool, you use Ollama with its c0mmands. You do not get a graphical user interface to interact with or manage models by default. However, you can install web UI tools or GUI front-ends to interact with AI models without needing the CLI. You can refer to our list here to explore options:
Ankush Das
Conclusion
Though there are plenty of similar tools, Ollama has become the most popular tool to run LLMs locally. The ease of use in installing different LLMs quickly make it ideal for beginners who want to use local AI.
I have tried to answer one of the most frequently asked questions you may have about Ollama. If you still have some questions, please feel free to ask in the comment section.
