

Tired of wrestling with LLM installations? Llamafiles offer a refreshingly simple way to run large language models on your own machine. Here's what you need to know.
Llamafile, is a cutting-edge solution from Mozilla that promises to revolutionize how we handle LLMs.
This innovative tool transforms LLM weights into executable files that can run seamlessly across multiple platforms with minimal hassle. Here's an in-depth look at what Llamafile is all about and why it matters.
What is Llamafile?
Llamafile is Mozilla's latest project aimed at simplifying the distribution and execution of large language models.
It combines the power of llama.cpp, an open-source LLM chatbot framework, with Cosmopolitan Libc, a versatile C library that ensures compatibility across a wide array of platforms.
The result? A tool that can transform complex model weights into easily executable files that run on various operating systems without any need for installation.
Key features include
- Cross-Platform Compatibility: Runs on macOS, Windows, Linux, FreeBSD, OpenBSD, and NetBSD, supporting multiple CPU architectures and GPU acceleration.
- Efficiency and Performance: Utilizes tinyBLAS for seamless GPU acceleration and recent optimizations for efficient CPU performance, making local AI more accessible.
- Ease of Use: Converts model weights into executable files with a single command, simplifying deployment.
- Open Source and Community-Driven: Licensed under Apache 2.0, encouraging community contributions and continuous improvements.
- Integration with Other Platforms: Supports external weights, adaptable to various use cases, and compatible with AI projects on platforms like Hugging Face.
Installing Llamafile
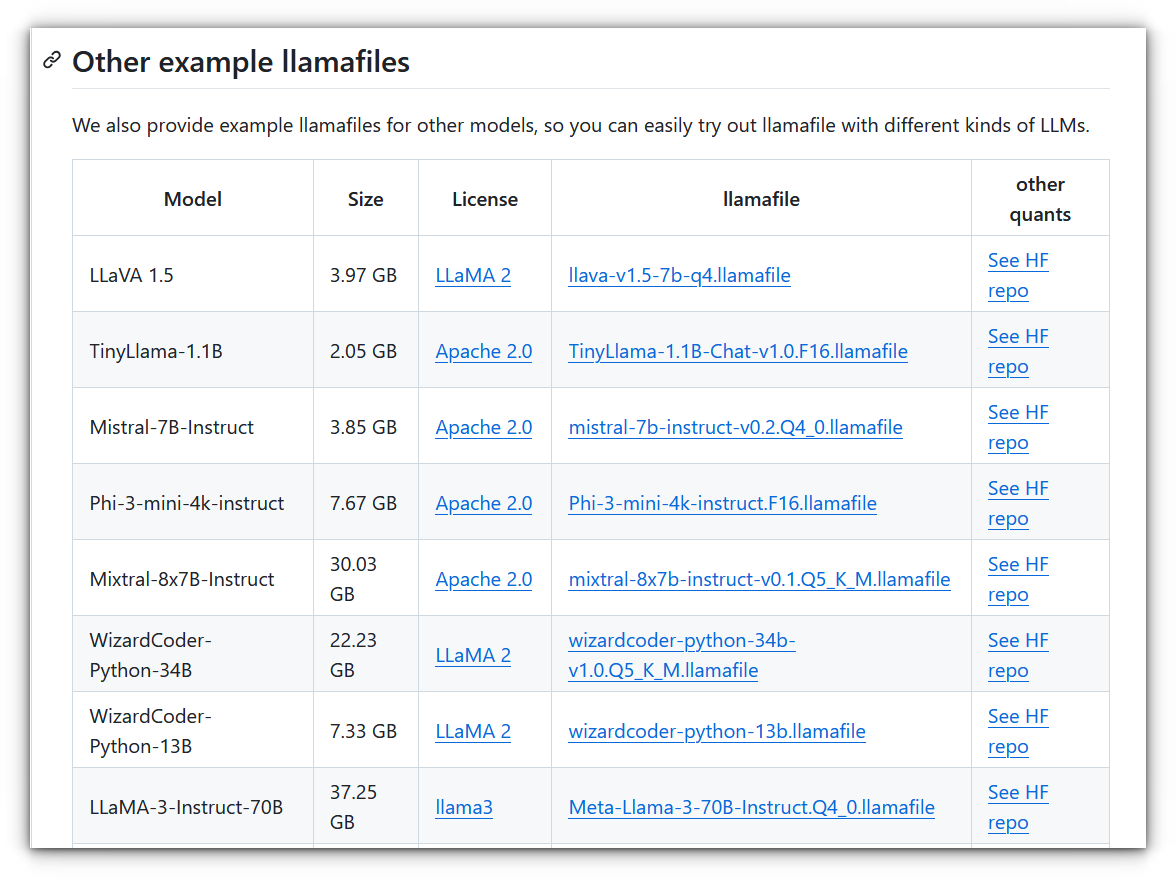
Head over to the GitHub releases page for llamafile. Choose the version you want, I will be using Mistral AI 7B model:
Make it executable (on Linux/macOS) and run
If you're using Linux or macOS, open a terminal window and navigate to the downloaded file.
Use the following command to grant executable permissions:
chmod +x mistral-7b-instruct-v0.2.Q4_0.llamafileOnce you make it executable, simply run the following command to start the llamafile server:
./mistral-7b-instruct-v0.2.Q4_0.llamafile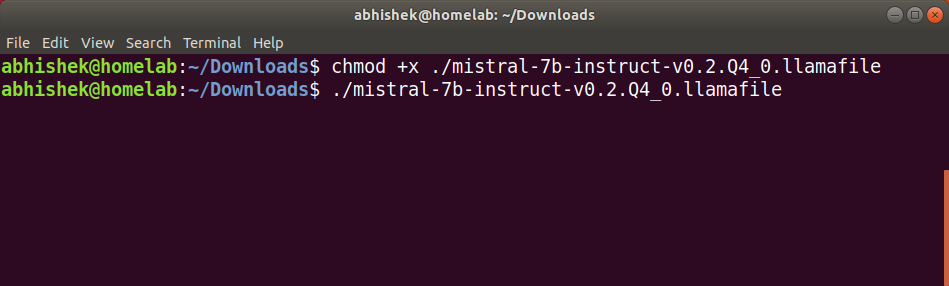
Once the server starts, it will display some information and a new browser window will open. You can interact with the LLM using text prompts, which we'll see in the next section.
Usage & Performance
I am testing this on an Intel 11th Gen CPU with 16 GB RAM and no discrete GPU and the performance seems okayish. The video below shows it in action:
GPU Acceleration (Optional): For faster processing, you can leverage your computer's GPU. This requires installing the appropriate drivers (NVIDIA CUDA for NVIDIA GPUs) and adding a flag during runtime (refer to the llamafile documentation for details).
Final Thoughts
Mozilla's Llamafile makes using large language models (LLMs) a lot simpler and more accessible.
Instead of dealing with the usual complicated setup, Llamafile lets you run powerful AI models with just a single executable file, making it easy for anyone, whether you're a developer or just curious to dive into AI experimentation.
However, the experience you get can vary based on your hardware; those with discrete GPUs will likely see better performance than those using integrated graphics.
Even so, Llamafile’s ability to run LLMs directly on your device means you don’t have to rely on expansive cloud services.
This not only keeps your data private and secure but also cuts down on response time, making AI interactions faster and more flexible.

