

As artificial intelligence continues to weave into our daily lives, there’s a noticeable shift towards smaller, more efficient language models that can run locally on devices.
SmolLM, part of a growing trend in compact language models, is a prime example, showing that we can bring AI closer to users without relying on heavy cloud-based infrastructure.
This article dives into the SmolLM experience on a Raspberry Pi using the 1.7B parameter model, exploring both its capabilities and how it holds up on limited hardware.
What is SmolLM?
SmolLM is a series of small, efficient language models designed for running on local devices without compromising too much on performance.
By leveraging optimized training datasets, including a mix of synthetic and educational content, SmolLM achieves a strong balance between power and efficiency.
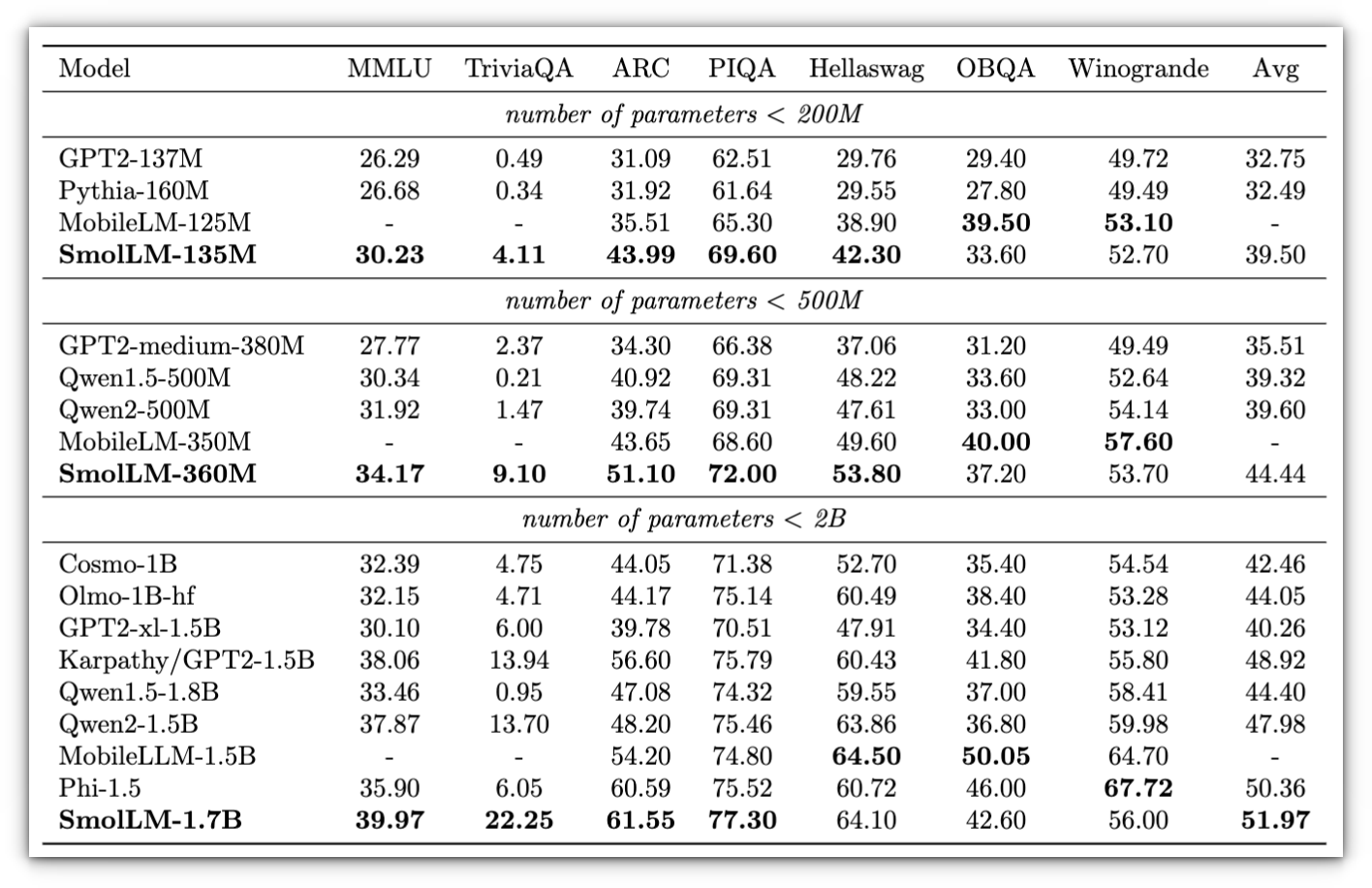
It comes in three sizes: 135M, 360M, and 1.7B parameters, with the latter providing the most depth in handling complex tasks.
At the core of SmolLM’s effectiveness is the SmolLM-Corpus, a carefully curated collection of datasets that enhance the model's understanding across various domains.
Key components of the corpus include:
- Cosmopedia v2: This dataset encompasses 28 billion tokens of synthetic textbooks and stories, providing a rich foundation of knowledge that enhances the model's ability to generate informative and contextually relevant responses.
- Python-Edu: Comprising 4 billion tokens, this dataset focuses on educational Python code samples. It equips SmolLM with a solid grasp of programming concepts, making it an ideal choice for applications in coding and technical education.
- FineWeb-Edu: This deduplicated dataset includes 220 billion tokens of educational web content, ensuring that the model has access to diverse and high-quality information, which is crucial for reasoning and inference tasks.
These components make SmolLM perform well on benchmarks focused on common sense and technical reasoning, all while maintaining a relatively compact model size.
Testing SmolLM on Raspberry Pi
To run SmolLM on a Raspberry Pi 5, I used Ollama in --verbose mode. This mode provides more insight into how SmolLM is processing tasks, which can be helpful in understanding model efficiency on the Pi’s hardware.
Below, you’ll find a video where I put SmolLM with 1.7B parameters to the test with the question:
"Explain the differences between a virtual machine and a Docker container in five sentences or less."
I was impressed by SmolLM's response speed and accuracy in answering the question. For a model of its size running on a Raspberry Pi, the response time was quite reasonable.
Here's the Verbose output:
total duration: 54.84240188s
load duration: 13.697837ms
prompt eval count: 28 token(s)
prompt eval duration: 2.387581s
prompt eval rate: 11.73 tokens/s
eval count: 393 token(s)
eval duration: 52.398543s
eval rate: 7.50 tokens/sThe output data provide a clear look at the model's speed and resource requirements. Here’s a breakdown of how it performed:
- Total Duration: The full operation took around 54.84 seconds, meaning that from start to finish, it consumed nearly a minute. This includes loading, evaluating prompts, and processing the model’s output.
- Load Duration: The model loaded almost instantly, taking only 13.70 milliseconds, demonstrating efficient initialization on Ollama.
- Prompt Evaluation: The initial prompt, consisting of 28 tokens, evaluated in 2.39 seconds, translating to a rate of approximately 11.73 tokens per second. This speed might be slightly restrictive for complex, multi-part prompts but is serviceable for shorter prompts.
- Model Evaluation: With 393 tokens processed in 52.40 seconds, the evaluation rate averaged 7.50 tokens per second. While not the fastest, this rate suggests that smolLM performs well for concise text generation, though it might lag for longer, more intensive tasks.
And where can we use SmolLM?
Small language models like SmolLM are designed to operate efficiently on modest hardware without relying on cloud-based services.
Their compact nature makes them well-suited for various applications, particularly in scenarios where local processing is crucial.
Here are some specific use cases highlighting the advantages of these models:
Mobile Applications
Small language models can enhance mobile devices by integrating directly into applications, reducing reliance on cloud services.
For instance, Apple Intelligence and Samsung's Galaxy AI utilize efficient AI to deliver quick responses to user queries while conserving battery life.
This allows for seamless interactions without the latency associated with cloud processing, making everyday tasks more efficient.
Local Customer Support
In customer service environments, small language models can power chatbots that run locally on devices.
This setup allows for quick, contextually relevant responses without the need for internet connectivity, ensuring continuous support even in offline scenarios.
Businesses benefit from enhanced user experiences and reduced operational costs by deploying effective, local AI solutions.
Educational Tools
SmolLM can be integrated into educational applications to generate customized learning materials directly on user devices.
This local processing capability ensures that sensitive data remains private and under the user's control, making it an appealing choice for educational institutions and learners who prioritize data security.
Code Assistance and Automation
Developers can utilize small language models for code generation and debugging tasks on their local machines.
By providing real-time suggestions and error identification without needing cloud connectivity, these models enhance productivity and streamline workflows, even on less powerful hardware.
Research and Prototyping
For AI researchers, small language models facilitate faster experimentation and prototyping.
Running locally allows researchers to iterate quickly without incurring the costs and limitations associated with cloud-based solutions. This flexibility fosters innovation and accelerates the development of new AI applications.
By leveraging their local processing capabilities, small language models like SmolLM and Phi provide a range of applications that empower users while minimizing reliance on external services.
Their ability to operate effectively on modest hardware makes them versatile tools across various domains, from mobile apps to customer support and educational platforms, ensuring that AI technology remains accessible and efficient.
Conclusion
SmolLM represents a transformative approach to AI, proving that smaller models can achieve remarkable results without the hefty resource demands of their larger counterparts.
By running SmolLM on a Raspberry Pi, we saw firsthand its impressive speed and accuracy, underscoring its potential for various applications.
As the industry shifts towards local deployment of AI technologies, the advantages of models like SmolLM will continue to grow.
This evolution not only enhances performance but also fosters a more privacy-conscious environment for users.
I believe that embracing such innovative models will pave the way for a new era of accessible and efficient AI solutions.

