

Since the launch of DeepSeek AI, every tech media outlet has been losing its mind over it. It's been shattering records, breaking benchmarks, and becoming the go-to name in AI innovation.
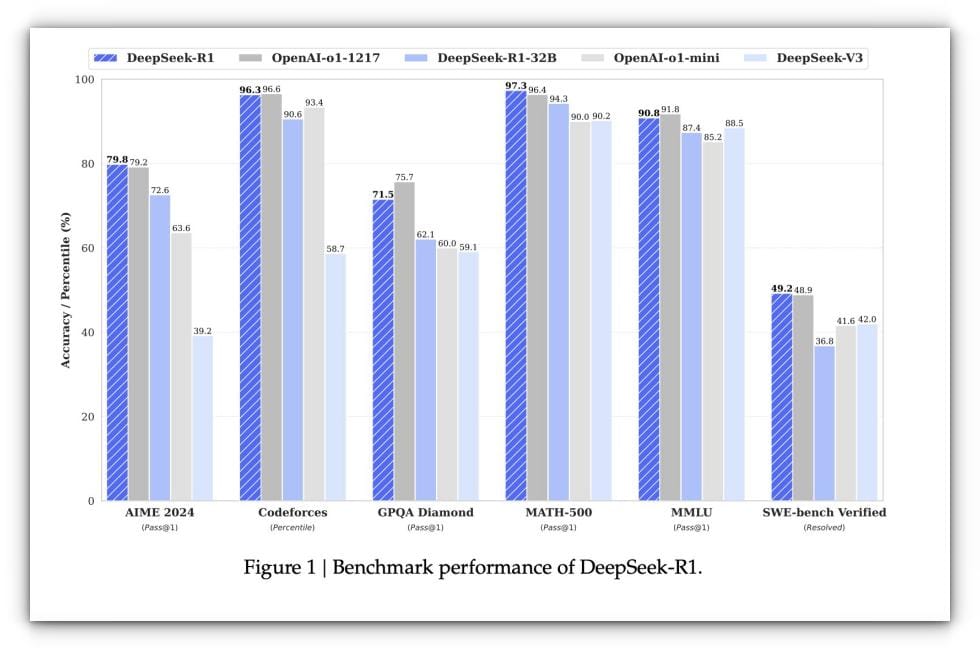
Recently, I stumbled upon a post on my X feed (don’t judge me, I’m moving to Bluesky soon!) where someone claimed to have run Deepseek on a Raspberry Pi at 200 tokens/second.

My head started spinning. "wHaaaTTT?!"
Naturally, I doom-scrolled the entire thread to make sense of it. Turns out, the guy used an AI accelerator module on top of the Pi to hit those numbers.
But curiosity is a powerful motivator. Since I didn’t have an AI module lying around, I thought, why not test the raw performance of Deepseek on a plain Raspberry Pi 5? Who's stopping me?
So, for this article, I installed Ollama on my Pi 5 (8 GB model) and downloaded Deepseek model with different parameters(i.e. 1.5B, 7B, 8B, and 14B parameters to be specific).

Here’s how each one performed:
Deepseek 1.5B
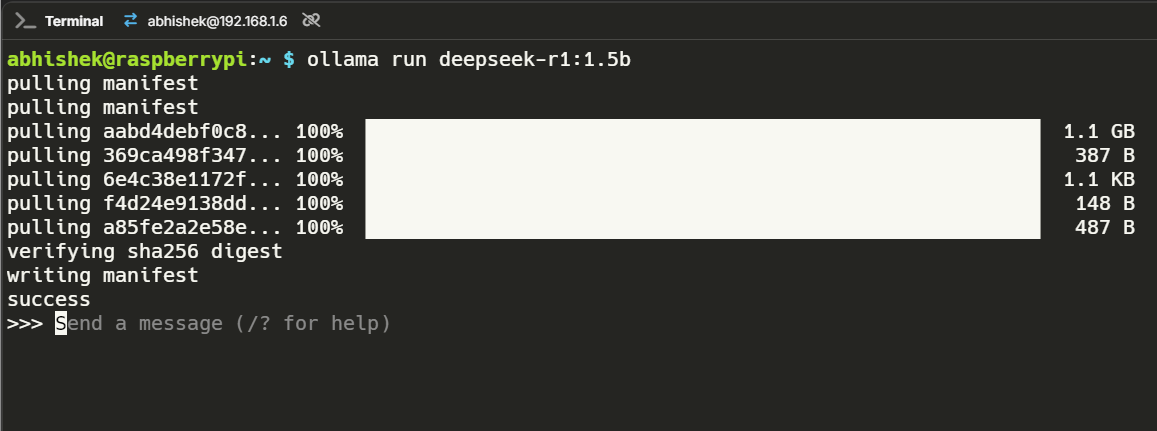
This model was snappy. It felt surprisingly responsive and handled paraphrasing tasks with ease. I didn’t encounter any hallucinations, making it a solid choice for day-to-day tasks like summarization and text generation.
Performance stats
To test its capability further, I posed the question: What's the difference between Podman and Docker?
The model gave a decent enough answer, clearly breaking down the differences between the two containerization tools.
It highlighted how Podman is daemonless, while Docker relies on a daemon, and touched on security aspects like rootless operation.
This response took about two minutes, and here’s how the performance data stacked up:
total duration: 1m33.59302487s
load duration: 44.322672ms
prompt eval count: 13 token(s)
prompt eval duration: 985ms
prompt eval rate: 13.20 tokens/s
eval count: 855 token(s)
eval duration: 1m32.562s
eval rate: 9.24 tokens/sDeepseek 7B
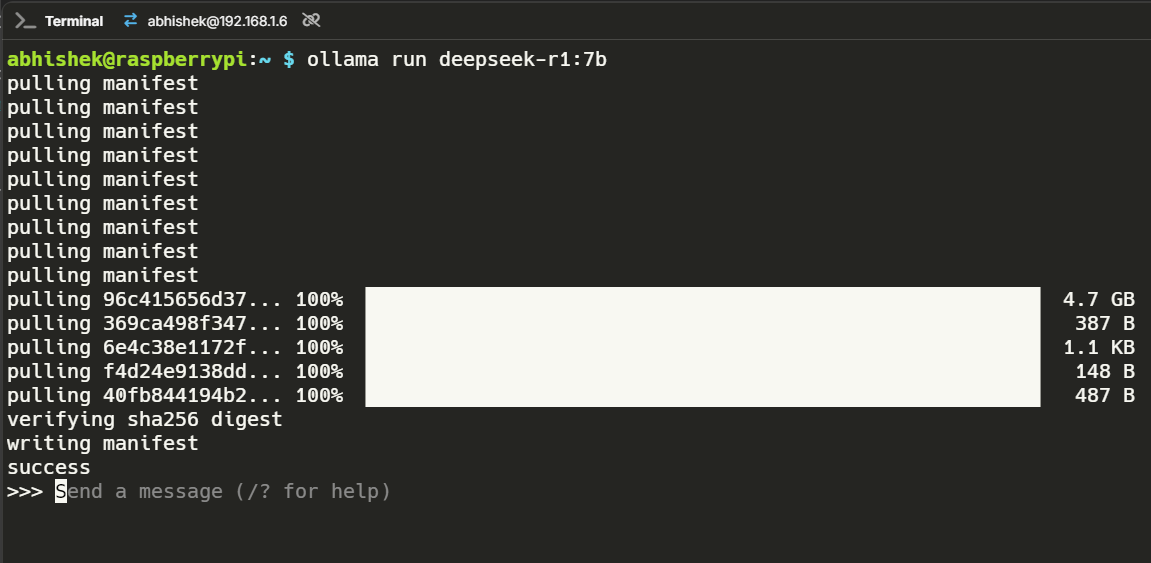
The 7B model introduced a fair amount of hallucination. I tried writing a creative prompt asking for three haikus, but it started generating endless text, even asking itself questions!
While amusing, it wasn’t exactly practical. For benchmarking purposes, I simplified my prompts, as seen in the video. Performance-wise, it was slower, but still functional.
Performance stats
To test it further, I asked: What’s the difference between Docker Compose and Docker Run? The response was a blend of accurate and imprecise information.
It correctly explained that Docker Compose is used to manage multi-container applications via a docker-compose.yml file, while Docker Run is typically for running single containers with specific flags.
However, it soon spiraled into asking itself questions like, “But for a single app, say a simple Flask app on a single machine, Docker Run might be sufficient? Or is there another command or method?”
Here’s how the performance data turned out:
total duration: 4m20.665430872s
load duration: 39.565944ms
prompt eval count: 11 token(s)
prompt eval duration: 3.256s
prompt eval rate: 3.38 tokens/s
eval count: 517 token(s)
eval duration: 4m17.368s
eval rate: 2.01 tokens/sDeepseek 8B
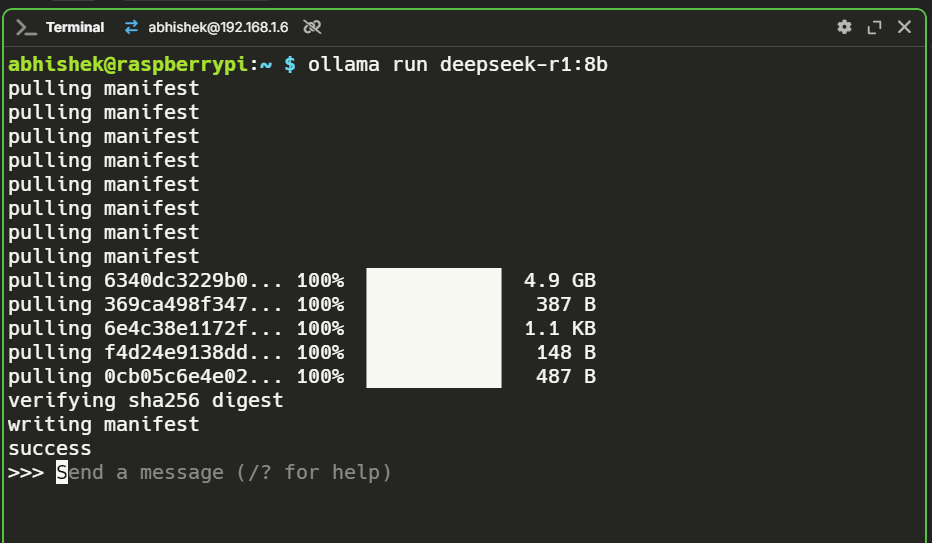
This was the wild card. I didn’t expect the 8B model to run at all, considering how resource-hungry these models are. To my surprise, it worked!
The performance was on par with the 7B model, neither fast nor particularly responsive, but hey, running an 8B model on a Raspberry Pi without extra hardware is a win in my book.
Performance stats
I tested it by asking, "Write an HTML boilerplate and CSS boilerplate." The model successfully generated a functional HTML and CSS boilerplate in a single code block, ensuring they were neatly paired.
However, before jumping into the solution, the model explained its approach, what it was going to do and what else could be added.
While this was informative, it felt unnecessary for a straightforward query. If I had crafted the prompt more precisely, the response might have been more direct (i.e. user error).
Here’s the performance breakdown:
total duration: 6m53.350371838s
load duration: 44.410437ms
prompt eval count: 13 token(s)
prompt eval duration: 4.99s
prompt eval rate: 2.61 tokens/s
eval count: 826 token(s)
eval duration: 6m48.314s
eval rate: 2.02 tokens/sDeepseek 14B ?
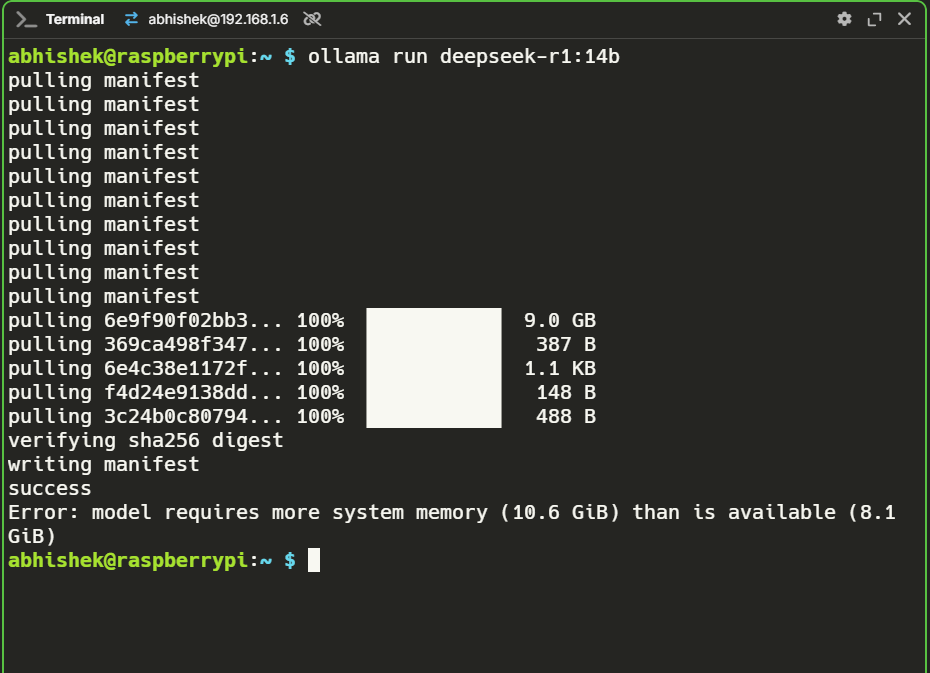
Unfortunately, this didn’t work. The 14B model required over 10 GB of RAM, which my 8 GB Pi couldn’t handle. After the success of the 8B model, my hopes were high, but alas, reality struck.
Conclusion
DeepSeek’s raw performance on the Raspberry Pi 5 showcases the growing potential of SBCs for AI workloads.
The 1.5B model is a practical option for lightweight tasks, while the 7B and 8B models demonstrate the Pi’s ability to handle larger workloads, albeit slowly.
I’m excited to test DeepSeek on the ArmSoM AIM7 with its 6 TOPS NPU. Its RK3588 SoC could unlock even better performance, and I’ll cover those results in a future article.
If you’re interested in more of my experiments, check out this article where I ran 9 popular LLMs on the Raspberry Pi 5.
Until then, happy tinkering, and remember: don’t ask AI to write haikus unless you want a never-ending saga. 😉

